27 The Importance of Early Attitudes Toward Mathematics and Science (Ing & Nylund-Gibson, 2017)
This document presents a replication of the latent transition analysis (LTA) conducted by Ing and Nylund-Gibson, (2017), which investigated how students’ attitudes toward mathematics and science evolve over time and how those attitudinal trajectories relate to later academic outcomes. Using nationally representative longitudinal data from the LSAY study, we follow students from Grade 7 to Grade 12, classifying them into latent attitudinal profiles at each wave and modeling transitions between those profiles across time. This replication reproduces the authors’ manual 3-step LTA approach, including: (1) estimating an invariant unconditional model to identify latent profiles across grades; (2) using fixed logits to classify students into profiles at each wave; and (3) examining how class membership and transitions relate to distal outcomes and demographic covariates. Where applicable, we extend the original analysis by visualizing transition patterns, computing subgroup differences using z-tests, and formatting outputs for clear interpretability.
27.1 Load Packages
library(tidyverse)
library(haven)
library(glue)
library(MplusAutomation)
library(here)
library(janitor)
library(gt)
library(cowplot)
library(DiagrammeR)
library(webshot2)
library(stringr)
library(flextable)
library(officer)
library(dplyr)
library(tidyr)
library(haven)
library(psych)
library(ggrepel)
library(PNWColors)
library(multcompView)
library(showtext)
showtext_auto()27.2 Prepare Data
lsay_data <- read_sav(here("tc_lta", "data", "Dataset_Jul9_Mplus.sav"))
# Filter to follow-up sample (target ~1824 rows)
lsay_data <- lsay_data %>% filter(RSTEMM %in% c(0, 1))
# Define survey questions
all_questions <- c(
"AB39A", "AB39H", "AB39I", "AB39K", "AB39L", "AB39M", "AB39T", "AB39U", "AB39W", "AB39X", # 7th grade
"GA32A", "GA32H", "GA32I", "GA32K", "GA32L", "GA33A", "GA33H", "GA33I", "GA33K", "GA33L", # 10th grade
"KA46A", "KA46H", "KA46I", "KA46K", "KA46L", "KA47A", "KA47H", "KA47I", "KA47K", "KA47L" # 12th grade
)
# Rename variables >8 characters
lsay_data <- lsay_data %>%
rename(
SCIG8 = ScienceG8,
SCIG11 = ScienceG11
)
# Recode 9999 to NA (missing)
lsay_data <- lsay_data %>%
mutate(across(all_of(all_questions), ~if_else(. == 9999, NA_real_, .)))
names(lsay_data) <- toupper(names(lsay_data))27.3 Descriptive Statistics
27.3.1 Create Table 1
This table provides the overall mean and standard deviation for each attitudinal item at Grades 7, 10, and 12. These values summarize general trends in the full sample and serve as a foundation for the latent class models that follow.
# Function to compute stats (count, mean, SD)
compute_stats <- function(data, question, grade, question_name) {
data %>%
summarise(
Grade = grade,
Count = sum(!is.na(.data[[question]])),
Mean = mean(.data[[question]], na.rm = TRUE),
SD = sd(.data[[question]], na.rm = TRUE)
) %>%
mutate(Question = question_name)
}
# Define question names and mappings
table_setup <- tibble(
question_code = all_questions,
grade = rep(c(7, 10, 12), each = 10),
question_name = rep(
c(
"I enjoy math",
"Math is useful in everyday problems",
"Math helps a person think logically",
"It is important to know math to get a good job",
"I will use math in many ways as an adult",
"I enjoy science",
"Science is useful in everyday problems",
"Science helps a person think logically",
"It is important to know science to get a good job",
"I will use science in many ways as an adult"
),
times = 3
)
)
# Compute stats for all questions
table1_data <- pmap_dfr(
list(table_setup$question_code, table_setup$grade, table_setup$question_name),
~compute_stats(lsay_data, ..1, ..2, ..3)
) %>%
mutate(
Mean = round(Mean, 2),
SD = round(SD, 2)
) %>%
arrange(match(Question, table_setup$question_name), Grade) %>%
select(Question, Grade, Count, Mean, SD)
# Build table
table1_gt <- table1_data %>%
gt(groupname_col = "Question") %>%
tab_header(
title = "Table 1. Descriptive Statistics for Mathematics and Science Attitudinal Survey Items Included In Analyses"
) %>%
cols_label(
Grade = "Grade",
Count = "N",
Mean = "M",
SD = "SD"
) %>%
fmt_number(
columns = c(Mean, SD),
decimals = 2
)
# Show table
table1_gt| Table 1. Descriptive Statistics for Mathematics and Science Attitudinal Survey Items Included In Analyses | |||
| Grade | N | M | SD |
|---|---|---|---|
| I enjoy math | |||
| 7 | 1882 | 0.69 | 0.46 |
| 10 | 1532 | 0.63 | 0.48 |
| 12 | 1120 | 0.57 | 0.50 |
| Math is useful in everyday problems | |||
| 7 | 1851 | 0.72 | 0.45 |
| 10 | 1520 | 0.65 | 0.48 |
| 12 | 1111 | 0.67 | 0.47 |
| Math helps a person think logically | |||
| 7 | 1847 | 0.65 | 0.48 |
| 10 | 1517 | 0.69 | 0.46 |
| 12 | 1108 | 0.71 | 0.45 |
| It is important to know math to get a good job | |||
| 7 | 1854 | 0.77 | 0.42 |
| 10 | 1517 | 0.68 | 0.47 |
| 12 | 1105 | 0.61 | 0.49 |
| I will use math in many ways as an adult | |||
| 7 | 1857 | 0.75 | 0.43 |
| 10 | 1525 | 0.65 | 0.48 |
| 12 | 1104 | 0.65 | 0.48 |
| I enjoy science | |||
| 7 | 1873 | 0.62 | 0.48 |
| 10 | 1526 | 0.59 | 0.49 |
| 12 | 1105 | 0.55 | 0.50 |
| Science is useful in everyday problems | |||
| 7 | 1840 | 0.40 | 0.49 |
| 10 | 1516 | 0.43 | 0.50 |
| 12 | 1099 | 0.48 | 0.50 |
| Science helps a person think logically | |||
| 7 | 1850 | 0.49 | 0.50 |
| 10 | 1516 | 0.53 | 0.50 |
| 12 | 1100 | 0.56 | 0.50 |
| It is important to know science to get a good job | |||
| 7 | 1857 | 0.40 | 0.49 |
| 10 | 1518 | 0.43 | 0.50 |
| 12 | 1099 | 0.38 | 0.49 |
| I will use science in many ways as an adult | |||
| 7 | 1873 | 0.46 | 0.50 |
| 10 | 1524 | 0.42 | 0.49 |
| 12 | 1103 | 0.44 | 0.50 |
Save Table 1
27.3.2 Create Table 2
This table presents model fit statistics for latent profile enumeration at Grades 7, 10, and 12. For each grade, models with 1 through 6 profiles were estimated and evaluated using the commonly used information criteria (AIC, BIC, SSA-BIC), entropy, and likelihood ratio tests (LMR, BLRT). These values help determine the most appropriate number of latent profiles to retain at each grade.
# Coerce to numeric just in case
lsay_data <- lsay_data %>%
mutate(
MATHG12 = as.numeric(MATHG12),
SCIG11 = as.numeric(SCIG11),
STEMSUP = as.numeric(STEMSUP)
)
# Build the summary table
table2_data <- tibble::tibble(
`Outcome Variable` = c(
"12th Grade Mathematics Achievement",
"11th Grade Science Achievement",
"STEM Career Attainmentᵃ"
),
N = c(
sum(lsay_data$MATHG12 != 9999 & !is.na(lsay_data$MATHG12)),
sum(lsay_data$SCIG11 != 9999 & !is.na(lsay_data$SCIG11)),
sum(lsay_data$STEMSUP != 9999 & !is.na(lsay_data$STEMSUP))
),
M = c(
round(mean(lsay_data$MATHG12[lsay_data$MATHG12 != 9999 & !is.na(lsay_data$MATHG12)]), 2),
round(mean(lsay_data$SCIG11[lsay_data$SCIG11 != 9999 & !is.na(lsay_data$SCIG11)]), 2),
round(mean(lsay_data$STEMSUP[lsay_data$STEMSUP != 9999 & !is.na(lsay_data$STEMSUP)]), 2)
),
SD = c(
round(sd(lsay_data$MATHG12[lsay_data$MATHG12 != 9999 & !is.na(lsay_data$MATHG12)]), 2),
round(sd(lsay_data$SCIG11[lsay_data$SCIG11 != 9999 & !is.na(lsay_data$SCIG11)]), 2),
NA
)
)
# Render the gt table
table2_gt <- table2_data %>%
gt() %>%
tab_header(
title = md("**Table 2. Descriptive Statistics for Distal Outcome Variables**")
) %>%
cols_label(
`Outcome Variable` = "Outcome Variable",
N = "N",
M = "M",
SD = "SD"
) %>%
sub_missing(columns = everything(), missing_text = "") %>%
tab_footnote(
footnote = "Binary indicator coded 1 = STEM occupation in mid-30s follow-up.",
locations = cells_body(rows = 3, columns = "Outcome Variable")
)
table2_gt| Table 2. Descriptive Statistics for Distal Outcome Variables | |||
| Outcome Variable | N | M | SD |
|---|---|---|---|
| 12th Grade Mathematics Achievement | 830 | 71.20 | 14.55 |
| 11th Grade Science Achievement | 1106 | 66.67 | 11.30 |
| STEM Career Attainmentᵃ1 | 1912 | 0.15 | |
| 1 Binary indicator coded 1 = STEM occupation in mid-30s follow-up. | |||
Save Table 2
27.4 Run Independent LCAs for Each Timepoint
27.4.1 Prepare Data for MPlusAutomation
To determine the appropriate number and structure of attitudinal profiles at each timepoint, we first estimate separate latent class models for Grades 7, 10, and 12. This step involves preparing the data in wide format and running independent LCAs using MplusAutomation. The goal is to identify the optimal number of latent profiles per grade based on model fit before moving to the longitudinal transition model.
27.4.2 Run LCA on 7th Grade Items
lca_belonging <- lapply(1:8, function(k) {
lca_enum <- mplusObject(
TITLE = glue("{k}-Class LCA for LSAY 7th Grade"),
VARIABLE = glue(
"categorical = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X;
usevar = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X;
missing = all(9999);
classes = c({k});"
),
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 500 10;
processors = 10;",
OUTPUT = "sampstat; residual; tech11; tech14;",
PLOT = "
type = plot3;
series = AB39A AB39H AB39I AB39K AB39L AB39M
AB39T AB39U AB39W AB39X(*);",
rdata = lsay_data
)
lca_enum_fit <- mplusModeler(
lca_enum,
dataout = glue(here("tc_lta","g7_enum", "lsay_g7.dat")),
modelout = glue(here("tc_lta","g7_enum", "c{k}_g7.inp")),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
})27.4.3 Run LCA on 10th Grade
lca_belonging <- lapply(1:8, function(k) {
lca_enum <- mplusObject(
TITLE = glue("{k}-Class LCA for LCA 10th Grade"),
VARIABLE = glue(
"categorical = GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L;
usevar = GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L;
missing = all(9999);
classes = c({k});"
),
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 500 10;
processors = 10;",
OUTPUT = "sampstat; residual; tech11; tech14;",
PLOT = "
type = plot3;
series = GA32A GA32H GA32I GA32K GA32L GA33A
GA33H GA33I GA33K GA33L (*);",
rdata = lsay_data
)
lca_enum_fit <- mplusModeler(
lca_enum,
dataout = glue(here("tc_lta","g10_enum", "lsay_g10.dat")),
modelout = glue(here("tc_lta","g10_enum", "c{k}_g10.inp")),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
})27.4.4 Run LCA for 12th Grade
lca_belonging <- lapply(1:8, function(k) {
lca_enum <- mplusObject(
TITLE = glue("{k}-Class LCA for LCA 12th Grade"),
VARIABLE = glue(
"categorical = KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L;
usevar = KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L;
missing = all(9999);
classes = c({k});"
),
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 500 10;
processors = 10;",
OUTPUT = "sampstat; residual; tech11; tech14;",
PLOT = "
type = plot3;
series = KA46A KA46H KA46I KA46K KA46L KA47A
KA47H KA47I KA47K KA47L (*);",
rdata = lsay_data
)
lca_enum_fit <- mplusModeler(
lca_enum,
dataout = glue(here("tc_lta","g12_enum", "lsay_g12.dat")),
modelout = glue(here("tc_lta","g12_enum", "c{k}_g12.inp")),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
})Extract Mplus Information
# LCA Extraction
source(here("tc_lta","functions", "extract_mplus_info.R"))
output_dir_lca <- here("tc_lta","enum")
output_files_lca <- list.files(output_dir_lca, pattern = "\\.out$", full.names = TRUE)
final_data_lca <- map_dfr(output_files_lca, extract_mplus_info_extended) %>%
mutate(Model_Type = "LCA")27.5 Screen Output for Warnings, Errors, and Loglikelihood Replication
After estimating each LCA model, we examine the Mplus output files for warnings, estimation errors, and loglikelihood replication issues. This quality check helps ensure that solutions are trustworthy and that selected models are not based on local maxima or convergence failures. In this step, we flag any estimation concerns and verify that the best loglikelihood value is replicated consistently across random starts.
Extract Warnings from Output Files
source(here("tc_lta","functions", "extract_mplus_info.R"))
# Extract 7th grade LCAs
output_dir_g7 <- here("tc_lta","g7_enum")
output_files_g7 <- list.files(output_dir_g7, pattern = "\\.out$", full.names = TRUE)
final_data_g7 <- map_dfr(output_files_g7, extract_mplus_info_extended) %>%
mutate(Model_Type = "LCA", Grade = "7th")
# Extract 10th grade LCAs
output_dir_g10 <- here("tc_lta","g10_enum")
output_files_g10 <- list.files(output_dir_g10, pattern = "\\.out$", full.names = TRUE)
final_data_g10 <- map_dfr(output_files_g10, extract_mplus_info_extended) %>%
mutate(Model_Type = "LCA", Grade = "10th")
# Extract 12th grade LCAs
output_dir_g12 <- here("tc_lta","g12_enum")
output_files_g12 <- list.files(output_dir_g12, pattern = "\\.out$", full.names = TRUE)
final_data_g12 <- map_dfr(output_files_g12, extract_mplus_info_extended) %>%
mutate(Model_Type = "LCA", Grade = "12th")27.5.1 Examine Output Warnings
source(here("tc_lta","functions", "extract_warnings.R"))
# ---- 7th Grade ----
warnings_g7 <- extract_warnings(final_data_g7) %>%
left_join(select(final_data_g7, File_Name), by = "File_Name")
warnings_table_g7 <- warnings_g7 %>%
gt() %>%
tab_header(title = md("**Model Warnings — 7th Grade LCA**")) %>%
cols_label(
File_Name = "Output File",
Warning_Summary = "# of Warnings",
Warnings = "Warning Message(s)"
) %>%
cols_align(align = "left", columns = everything()) %>%
cols_width(
File_Name ~ px(150),
Warning_Summary ~ px(150),
Warnings ~ px(400)
) %>%
tab_options(table.width = pct(100))
# ---- 10th Grade ----
warnings_g10 <- extract_warnings(final_data_g10) %>%
left_join(select(final_data_g10, File_Name), by = "File_Name")
warnings_table_g10 <- warnings_g10 %>%
gt() %>%
tab_header(title = md("**Model Warnings — 10th Grade LCA**")) %>%
cols_label(
File_Name = "Output File",
Warning_Summary = "# of Warnings",
Warnings = "Warning Message(s)"
) %>%
cols_align(align = "left", columns = everything()) %>%
cols_width(
File_Name ~ px(150),
Warning_Summary ~ px(150),
Warnings ~ px(400)
) %>%
tab_options(table.width = pct(100))
# ---- 12th Grade ----
warnings_g12 <- extract_warnings(final_data_g12) %>%
left_join(select(final_data_g12, File_Name), by = "File_Name")
warnings_table_g12 <- warnings_g12 %>%
gt() %>%
tab_header(title = md("**Model Warnings — 12th Grade LCA**")) %>%
cols_label(
File_Name = "Output File",
Warning_Summary = "# of Warnings",
Warnings = "Warning Message(s)"
) %>%
cols_align(align = "left", columns = everything()) %>%
cols_width(
File_Name ~ px(150),
Warning_Summary ~ px(150),
Warnings ~ px(400)
) %>%
tab_options(table.width = pct(100))
# Print all three
warnings_table_g7| Model Warnings — 7th Grade LCA | ||
| Output File | # of Warnings | Warning Message(s) |
|---|---|---|
| c1_g7.out | There are 4 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING in OUTPUT command TECH11 option is not available for TYPE=MIXTURE with only one class. Request for TECH11 is ignored. | ||
| *** WARNING in OUTPUT command TECH14 option is not available for TYPE=MIXTURE with only one class. Request for TECH14 is ignored. | ||
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c2_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c3_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c4_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c5_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c6_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c7_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
| c8_g7.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 26 | ||
warnings_table_g10| Model Warnings — 10th Grade LCA | ||
| Output File | # of Warnings | Warning Message(s) |
|---|---|---|
| c1_g10.out | There are 4 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING in OUTPUT command TECH11 option is not available for TYPE=MIXTURE with only one class. Request for TECH11 is ignored. | ||
| *** WARNING in OUTPUT command TECH14 option is not available for TYPE=MIXTURE with only one class. Request for TECH14 is ignored. | ||
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c2_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c3_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c4_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c5_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c6_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c7_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
| c8_g10.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 378 | ||
warnings_table_g12| Model Warnings — 12th Grade LCA | ||
| Output File | # of Warnings | Warning Message(s) |
|---|---|---|
| c1_g12.out | There are 4 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING in OUTPUT command TECH11 option is not available for TYPE=MIXTURE with only one class. Request for TECH11 is ignored. | ||
| *** WARNING in OUTPUT command TECH14 option is not available for TYPE=MIXTURE with only one class. Request for TECH14 is ignored. | ||
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c2_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c3_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c4_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c5_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c6_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c7_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
| c8_g12.out | There are 2 warnings in the output file. | *** WARNING in OUTPUT command SAMPSTAT option is not available when all outcomes are censored, ordered categorical, unordered categorical (nominal), count or continuous-time survival variables. Request for SAMPSTAT is ignored. |
| *** WARNING Data set contains cases with missing on all variables. These cases were not included in the analysis. Number of cases with missing on all variables: 790 | ||
Save Warning Tables
gtsave(warnings_table_g7, filename = here("tc_lta","figures", "warnings_g7_lca.png"))
gtsave(warnings_table_g10, filename = here("tc_lta","figures", "warnings_g10_lca.png"))
gtsave(warnings_table_g12, filename = here("tc_lta","figures", "warnings_g12_lca.png"))Extract Errors from Output Files
source(here("tc_lta","functions", "error_visualization.R"))
# ---- 7th Grade Errors ----
error_table_g7 <- process_error_data(final_data_g7)
# ---- 10th Grade Errors ----
error_table_g10 <- process_error_data(final_data_g10)
# ---- 12th Grade Errors ----
error_table_g12 <- process_error_data(final_data_g12)27.5.2 Examine Errors
# Helper to conditionally render or notify
render_error_table <- function(error_df, grade_label) {
if (nrow(error_df) > 0) {
error_df %>%
gt() %>%
tab_header(title = md(glue("**Model Estimation Errors — {grade_label} Grade**"))) %>%
cols_label(
File_Name = "Output File",
Class_Model = "Model Type",
Error_Message = "Error Message"
) %>%
cols_align(align = "left", columns = everything()) %>%
cols_width(
File_Name ~ px(150),
Class_Model ~ px(100),
Error_Message ~ px(400)
) %>%
tab_options(table.width = px(600)) %>%
fmt(
columns = "Error_Message",
fns = function(x) gsub("\n", "<br>", x)
)
} else {
cat(glue("✅ No errors detected for {grade_label} Grade.\n"))
}
}
# Print or notify for each grade
render_error_table(error_table_g7, "7th")| Model Estimation Errors — 7th Grade | ||
| Output File | Model Type | Error Message |
|---|---|---|
| c2_g7.out | 2-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c3_g7.out | 3-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c4_g7.out | 4-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c5_g7.out | 5-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c6_g7.out | 6-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c7_g7.out | 7-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c8_g7.out | 8-Class | SOLUTION MAY NOT BE TRUSTWORTHY DUE TO LOCAL MAXIMA. INCREASE THE NUMBER OF RANDOM STARTS. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
render_error_table(error_table_g10, "10th")| Model Estimation Errors — 10th Grade | ||
| Output File | Model Type | Error Message |
|---|---|---|
| c2_g10.out | 2-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c3_g10.out | 3-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c4_g10.out | 4-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c5_g10.out | 5-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c6_g10.out | 6-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c7_g10.out | 7-Class | SOLUTION MAY NOT BE TRUSTWORTHY DUE TO LOCAL MAXIMA. INCREASE THE NUMBER OF RANDOM STARTS. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c8_g10.out | 8-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. THE STANDARD ERRORS OF THE MODEL PARAMETER ESTIMATES MAY NOT BE TRUSTWORTHY FOR SOME PARAMETERS DUE TO A NON-POSITIVE DEFINITE FIRST-ORDER DERIVATIVE PRODUCT MATRIX. THIS MAY BE DUE TO THE STARTING VALUES BUT MAY ALSO BE AN INDICATION OF MODEL NONIDENTIFICATION. THE CONDITION NUMBER IS 0.526D-11. PROBLEM INVOLVING THE FOLLOWING PARAMETER: Parameter 28, %C#3%: [ GA33I$1 ] |
render_error_table(error_table_g12, "12th")| Model Estimation Errors — 12th Grade | ||
| Output File | Model Type | Error Message |
|---|---|---|
| c2_g12.out | 2-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c3_g12.out | 3-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c4_g12.out | 4-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. |
| c5_g12.out | 5-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
| c6_g12.out | 6-Class | RANDOM STARTS TO CHECK THAT THE BEST LOGLIKELIHOOD IS STILL OBTAINED AND REPLICATED. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. THE STANDARD ERRORS OF THE MODEL PARAMETER ESTIMATES MAY NOT BE TRUSTWORTHY FOR SOME PARAMETERS DUE TO A NON-POSITIVE DEFINITE FIRST-ORDER DERIVATIVE PRODUCT MATRIX. THIS MAY BE DUE TO THE STARTING VALUES BUT MAY ALSO BE AN INDICATION OF MODEL NONIDENTIFICATION. THE CONDITION NUMBER IS 0.212D-11. PROBLEM INVOLVING THE FOLLOWING PARAMETER: Parameter 39, %C#4%: [ KA47K$1 ] |
| c7_g12.out | 7-Class | SOLUTION MAY NOT BE TRUSTWORTHY DUE TO LOCAL MAXIMA. INCREASE THE NUMBER OF RANDOM STARTS. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. THE STANDARD ERRORS OF THE MODEL PARAMETER ESTIMATES MAY NOT BE TRUSTWORTHY FOR SOME PARAMETERS DUE TO A NON-POSITIVE DEFINITE FIRST-ORDER DERIVATIVE PRODUCT MATRIX. THIS MAY BE DUE TO THE STARTING VALUES BUT MAY ALSO BE AN INDICATION OF MODEL NONIDENTIFICATION. THE CONDITION NUMBER IS 0.120D-13. PROBLEM INVOLVING THE FOLLOWING PARAMETER: Parameter 16, %C#2%: [ KA47A$1 ] |
| c8_g12.out | 8-Class | SOLUTION MAY NOT BE TRUSTWORTHY DUE TO LOCAL MAXIMA. INCREASE THE NUMBER OF RANDOM STARTS. IN THE OPTIMIZATION, ONE OR MORE LOGIT THRESHOLDS APPROACHED EXTREME VALUES OF -15.000 AND 15.000 AND WERE FIXED TO STABILIZE MODEL ESTIMATION. THESE VALUES IMPLY PROBABILITIES OF 0 AND 1. IN THE MODEL RESULTS SECTION, THESE PARAMETERS HAVE 0 STANDARD ERRORS AND 999 IN THE Z-SCORE AND P-VALUE COLUMNS. |
Save Error Tables
if (exists("error_table_g7") && nrow(error_table_g7) > 0) {
gtsave(render_error_table(error_table_g7, "7th"), here("tc_lta","figures", "errors_g7_lca.png"))
}
if (exists("error_table_g10") && nrow(error_table_g10) > 0) {
gtsave(render_error_table(error_table_g10, "10th"), here("tc_lta","figures", "errors_g10_lca.png"))
}
if (exists("error_table_g12") && nrow(error_table_g12) > 0) {
gtsave(render_error_table(error_table_g12, "12th"), here("tc_lta","figures", "errors_g12_lca.png"))
}27.5.3 Examine Convergence Information
# Load function
source(here("tc_lta","functions", "summary_table.R"))
# Helper: clean + prep for each dataset
prepare_convergence_table <- function(data_object, grade_label) {
sample_size <- data_object$Sample_Size[1]
data_flat <- data_object %>%
select(-LogLikelihoods, -Errors, -Warnings) %>%
mutate(across(
c(
Best_LogLikelihood,
Perc_Convergence,
Replicated_LL_Perc,
Smallest_Class_Perc,
Condition_Number
),
~ as.numeric(gsub(",", "", .))
))
tbl <- create_flextable(data_flat, sample_size)
# Get actual number of columns in the flextable object
n_cols <- length(tbl$body$col_keys)
# Title string
title_text <- glue("LCA Convergence Table — {grade_label} Grade (N = {sample_size})")
# This is the correct call: title as one string, colwidth = full span
tbl <- add_header_row(
tbl,
values = title_text,
colwidths = n_cols
) %>%
align(i = 1, align = "center", part = "header") %>%
fontsize(i = 1, size = 12, part = "header") %>%
bg(i = 1, bg = "#ffffff", part = "header")
return(tbl)
}
# Create tables
summary_table_g7 <- prepare_convergence_table(final_data_g7, "7th")
summary_table_g10 <- prepare_convergence_table(final_data_g10, "10th")
summary_table_g12 <- prepare_convergence_table(final_data_g12, "12th")
summary_table_g7 LCA Convergence Table — 7th Grade (N = 1886) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
N = 1886 |
Random Starts |
Final starts converging |
LL Replication |
Smallest Class |
||||||
Model |
Best LL |
npar |
Initial |
Final |
𝒇 |
% |
𝒇 |
% |
𝒇 |
% |
1-Class |
-11,803.429 |
10 |
500 |
10 |
10 |
100% |
10 |
100% |
1,886 |
100.0% |
2-Class |
-10,418.761 |
21 |
500 |
10 |
10 |
100% |
10 |
100% |
782 |
41.5% |
3-Class |
-10,165.874 |
32 |
500 |
10 |
10 |
100% |
10 |
100% |
384 |
20.4% |
4-Class |
-10,042.970 |
43 |
500 |
10 |
10 |
100% |
10 |
100% |
390 |
20.7% |
5-Class |
-9,969.239 |
54 |
500 |
10 |
10 |
100% |
6 |
60% |
175 |
9.3% |
6-Class |
-9,915.148 |
65 |
500 |
10 |
10 |
100% |
8 |
80% |
180 |
9.5% |
7-Class |
-9,891.204 |
76 |
500 |
10 |
10 |
100% |
5 |
50% |
47 |
2.5% |
8-Class |
-9,871.411 |
87 |
500 |
10 |
10 |
100% |
1 |
10% |
55 |
2.9% |
summary_table_g10LCA Convergence Table — 10th Grade (N = 1534) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
N = 1534 |
Random Starts |
Final starts converging |
LL Replication |
Smallest Class |
||||||
Model |
Best LL |
npar |
Initial |
Final |
𝒇 |
% |
𝒇 |
% |
𝒇 |
% |
1-Class |
-10,072.926 |
10 |
500 |
10 |
10 |
100% |
10 |
100% |
1,534 |
100.0% |
2-Class |
-8,428.384 |
21 |
500 |
10 |
10 |
100% |
10 |
100% |
658 |
42.9% |
3-Class |
-8,067.612 |
32 |
500 |
10 |
10 |
100% |
10 |
100% |
297 |
19.4% |
4-Class |
-7,905.535 |
43 |
500 |
10 |
10 |
100% |
10 |
100% |
290 |
18.9% |
5-Class |
-7,845.441 |
54 |
500 |
10 |
10 |
100% |
10 |
100% |
220 |
14.3% |
6-Class |
-7,806.987 |
65 |
500 |
10 |
10 |
100% |
3 |
30% |
130 |
8.5% |
7-Class |
-7,779.821 |
76 |
500 |
10 |
10 |
100% |
1 |
10% |
62 |
4.1% |
8-Class |
-7,754.190 |
87 |
500 |
10 |
10 |
100% |
2 |
20% |
84 |
5.5% |
summary_table_g12LCA Convergence Table — 12th Grade (N = 1122) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
N = 1122 |
Random Starts |
Final starts converging |
LL Replication |
Smallest Class |
||||||
Model |
Best LL |
npar |
Initial |
Final |
𝒇 |
% |
𝒇 |
% |
𝒇 |
% |
1-Class |
-7,349.129 |
10 |
500 |
10 |
10 |
100% |
10 |
100% |
1,122 |
100.0% |
2-Class |
-5,976.598 |
21 |
500 |
10 |
10 |
100% |
10 |
100% |
534 |
47.5% |
3-Class |
-5,670.595 |
32 |
500 |
10 |
10 |
100% |
10 |
100% |
203 |
18.1% |
4-Class |
-5,543.616 |
43 |
500 |
10 |
10 |
100% |
10 |
100% |
219 |
19.5% |
5-Class |
-5,483.669 |
54 |
500 |
10 |
10 |
100% |
9 |
90% |
131 |
11.7% |
6-Class |
-5,444.055 |
65 |
500 |
10 |
10 |
100% |
5 |
50% |
81 |
7.2% |
7-Class |
-5,420.551 |
76 |
500 |
10 |
10 |
100% |
1 |
10% |
44 |
3.9% |
8-Class |
-5,395.532 |
87 |
500 |
10 |
10 |
100% |
1 |
10% |
61 |
5.4% |
Save Convergence Tables
# Save convergence tables as PNGs
invisible(save_as_image(summary_table_g7, path = here("tc_lta","figures", "convergence_g7_lca.png")))
invisible(save_as_image(summary_table_g10, path = here("tc_lta","figures", "convergence_g10_lca.png")))
invisible(save_as_image(summary_table_g12, path = here("tc_lta","figures", "convergence_g12_lca.png")))Scrape Replication Data
27.5.4 Examine Loglikelihood Replication Information
# Generate replication plots (invisible, for diagnostic use)
ll_replication_tables_g7 <- generate_ll_replication_plots(final_data_g7)
ll_replication_tables_g10 <- generate_ll_replication_plots(final_data_g10)
ll_replication_tables_g12 <- generate_ll_replication_plots(final_data_g12)
# Create replication tables
ll_replication_table_g7 <- create_ll_replication_table_all(final_data_g7)
ll_replication_table_g10 <- create_ll_replication_table_all(final_data_g10)
ll_replication_table_g12 <- create_ll_replication_table_all(final_data_g12)
# Add visible title row to each table
ll_replication_table_g7 <- add_header_row(
ll_replication_table_g7,
values = "Log-Likelihood Replication Table — 7th Grade LCA",
colwidths = ncol(ll_replication_table_g7$body$dataset)
) %>%
align(i = 1, align = "center", part = "header") %>%
fontsize(i = 1, size = 12, part = "header") %>%
bg(i = 1, bg = "#ffffff", part = "header")
ll_replication_table_g10 <- add_header_row(
ll_replication_table_g10,
values = "Log-Likelihood Replication Table — 10th Grade LCA",
colwidths = ncol(ll_replication_table_g10$body$dataset)
) %>%
align(i = 1, align = "center", part = "header") %>%
fontsize(i = 1, size = 12, part = "header") %>%
bg(i = 1, bg = "#ffffff", part = "header")
ll_replication_table_g12 <- add_header_row(
ll_replication_table_g12,
values = "Log-Likelihood Replication Table — 12th Grade LCA",
colwidths = ncol(ll_replication_table_g12$body$dataset)
) %>%
align(i = 1, align = "center", part = "header") %>%
fontsize(i = 1, size = 12, part = "header") %>%
bg(i = 1, bg = "#ffffff", part = "header")
# Display the three titled tables
ll_replication_table_g7Log-Likelihood Replication Table — 7th Grade LCA | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1-Class |
2-Class |
3-Class |
4-Class |
5-Class |
6-Class |
7-Class |
8-Class |
||||||||||||||||
LL_c1 |
n_c1 |
perc_c1 |
LL_c2 |
n_c2 |
perc_c2 |
LL_c3 |
n_c3 |
perc_c3 |
LL_c4 |
n_c4 |
perc_c4 |
LL_c5 |
n_c5 |
perc_c5 |
LL_c6 |
n_c6 |
perc_c6 |
LL_c7 |
n_c7 |
perc_c7 |
LL_c8 |
n_c8 |
perc_c8 |
-11803.429 |
10 |
100 |
-10418.761 |
10 |
100 |
-10165.874 |
10 |
100 |
-10042.97 |
10 |
100 |
-9969.239 |
6 |
60 |
-9915.148 |
8 |
80 |
-9891.204 |
5 |
50 |
-9,871.411 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9969.697 |
4 |
40 |
-9915.778 |
1 |
10 |
-9893.864 |
1 |
10 |
-9,872.124 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9916.262 |
1 |
10 |
-9894.265 |
1 |
10 |
-9,874.200 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9898.309 |
1 |
10 |
-9,876.173 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9904.214 |
1 |
10 |
-9,876.914 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9904.532 |
1 |
10 |
-9,877.583 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9,877.741 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9,877.806 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9,879.960 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-9,888.932 |
1 |
10 |
ll_replication_table_g10Log-Likelihood Replication Table — 10th Grade LCA | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1-Class |
2-Class |
3-Class |
4-Class |
5-Class |
6-Class |
7-Class |
8-Class |
||||||||||||||||
LL_c1 |
n_c1 |
perc_c1 |
LL_c2 |
n_c2 |
perc_c2 |
LL_c3 |
n_c3 |
perc_c3 |
LL_c4 |
n_c4 |
perc_c4 |
LL_c5 |
n_c5 |
perc_c5 |
LL_c6 |
n_c6 |
perc_c6 |
LL_c7 |
n_c7 |
perc_c7 |
LL_c8 |
n_c8 |
perc_c8 |
-10072.926 |
10 |
100 |
-8428.384 |
10 |
100 |
-8067.612 |
10 |
100 |
-7905.535 |
10 |
100 |
-7845.441 |
10 |
100 |
-7806.987 |
3 |
30 |
-7779.821 |
1 |
10 |
-7,754.190 |
2 |
20 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7807.464 |
4 |
40 |
-7780.664 |
5 |
50 |
-7,754.206 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7807.485 |
1 |
10 |
-7781.893 |
1 |
10 |
-7,757.915 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7808.751 |
1 |
10 |
-7783.866 |
1 |
10 |
-7,758.288 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7820.453 |
1 |
10 |
-7784.195 |
1 |
10 |
-7,759.634 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7784.933 |
1 |
10 |
-7,759.730 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7,760.773 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7,762.451 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-7,762.777 |
1 |
10 |
ll_replication_table_g12Log-Likelihood Replication Table — 12th Grade LCA | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
1-Class |
2-Class |
3-Class |
4-Class |
5-Class |
6-Class |
7-Class |
8-Class |
||||||||||||||||
LL_c1 |
n_c1 |
perc_c1 |
LL_c2 |
n_c2 |
perc_c2 |
LL_c3 |
n_c3 |
perc_c3 |
LL_c4 |
n_c4 |
perc_c4 |
LL_c5 |
n_c5 |
perc_c5 |
LL_c6 |
n_c6 |
perc_c6 |
LL_c7 |
n_c7 |
perc_c7 |
LL_c8 |
n_c8 |
perc_c8 |
-7349.129 |
10 |
100 |
-5976.598 |
10 |
100 |
-5670.595 |
10 |
100 |
-5543.616 |
10 |
100 |
-5483.669 |
9 |
90 |
-5444.055 |
5 |
50 |
-5420.551 |
1 |
10 |
-5,395.532 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5484.101 |
1 |
10 |
-5446.399 |
4 |
40 |
-5421.469 |
1 |
10 |
-5,397.310 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5446.424 |
1 |
10 |
-5421.554 |
2 |
20 |
-5,397.311 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5421.845 |
1 |
10 |
-5,398.708 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5422.176 |
1 |
10 |
-5,399.930 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5423.003 |
1 |
10 |
-5,400.458 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5424.777 |
1 |
10 |
-5,400.463 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5426.79 |
1 |
10 |
-5,401.156 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5427.065 |
1 |
10 |
-5,403.971 |
1 |
10 |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
— |
-5,405.328 |
1 |
10 |
Save LL Replication Tables
invisible({
flextable::save_as_image(ll_replication_table_g7, path = here::here("tc_lta","figures", "ll_replication_table_g7.png"))
flextable::save_as_image(ll_replication_table_g10, path = here::here("tc_lta","figures", "ll_replication_table_g10.png"))
flextable::save_as_image(ll_replication_table_g12, path = here::here("tc_lta","figures", "ll_replication_table_g12.png"))
})27.6 Examine Model Fit for Optimal Solution
We evaluate model fit for each grade-level LCA to identify the optimal number of latent profiles. Fit statistics such as BIC, entropy, and likelihood ratio tests (LMR and BLRT) are compared across models. The goal is to select the most parsimonious solution that provides clear separation between classes and replicates reliably. These selections will form the basis for the longitudinal model in the next stage.
Extract fit statistics
# Define grade-specific folders and data
grades <- c("g7", "g10", "g12")
folder_paths <- c(
g7 = here("tc_lta","g7_enum"),
g10 = here("tc_lta","g10_enum"),
g12 = here("tc_lta","g12_enum")
)
final_data_list <- list(
g7 = final_data_g7,
g10 = final_data_g10,
g12 = final_data_g12
)
# Initialize storage
output_models_all <- list()
allFit_list <- list()
# Process each grade
for (grade in grades) {
# Get all .out files (1-8 classes)
out_files <- list.files(folder_paths[grade], pattern = "^c[1-8]_g\\d+\\.out$", full.names = TRUE)
# Read Mplus output files
output_models <- list()
for (file in out_files) {
model <- readModels(file, quiet = TRUE)
if (!is.null(model) && length(model) > 0) {
output_models[[basename(file)]] <- model
}
}
# Store models
output_models_all[[grade]] <- output_models
# Extract summary table
model_extract <- LatexSummaryTable(
output_models,
keepCols = c("Title", "Parameters", "LL", "BIC", "aBIC", "T11_VLMR_PValue", "BLRT_PValue", "Observations", "Entropy"),
sortBy = "Title"
)
# Compute additional fit indices
allFit <- model_extract %>%
mutate(
Title = str_trim(Title),
Grade = toupper(grade),
Classes = as.integer(str_extract(Title, "\\d+")), # Extract class number
File_Name = names(output_models),
CAIC = -2 * LL + Parameters * (log(Observations) + 1),
AWE = -2 * LL + 2 * Parameters * (log(Observations) + 1.5),
SIC = -0.5 * BIC,
expSIC = exp(SIC - max(SIC, na.rm = TRUE)),
BF = if_else(is.na(lead(SIC)), NA_real_, exp(SIC - lead(SIC))),
cmPk = expSIC / sum(expSIC, na.rm = TRUE)
) %>%
arrange(Classes)
# Clean Class_Model for joining
final_data_clean <- final_data_list[[grade]] %>%
mutate(
Classes = as.integer(str_extract(Class_Model, "\\d+"))
) %>%
select(Class_Model, Classes, Perc_Convergence, Replicated_LL_Perc, Smallest_Class, Smallest_Class_Perc)
# Merge with final_data
allFit <- allFit %>%
left_join(
final_data_clean,
by = "Classes"
) %>%
mutate(
Smallest_Class_Combined = paste0(Smallest_Class, "\u00A0(", Smallest_Class_Perc, "%)")
) %>%
relocate(Grade, Classes, Parameters, LL, Perc_Convergence, Replicated_LL_Perc, .before = BIC) %>%
select(
Grade, Classes, Parameters, LL, Perc_Convergence, Replicated_LL_Perc,
BIC, aBIC, CAIC, AWE, T11_VLMR_PValue, BLRT_PValue, Entropy, Smallest_Class_Combined, BF, cmPk
)
# Store fit data
allFit_list[[grade]] <- allFit
}
# Combine fit data
allFit_combined <- bind_rows(allFit_list) %>%
arrange(Grade, Classes)27.6.1 Examine Fit Statistics
# Initialize list to store tables
fit_tables <- list()
# Create and render table for each grade
for (grade in grades) {
# Filter data for current grade
allFit_grade <- allFit_combined %>%
filter(Grade == toupper(grade)) %>%
select(-Perc_Convergence, -Replicated_LL_Perc) # Exclude convergence columns
# Create table
fit_table <- allFit_grade %>%
gt() %>%
tab_header(title = md(sprintf("**Model Fit Summary Table for %s Grade**", toupper(grade)))) %>%
tab_spanner(label = "Model Fit Indices", columns = c(BIC, aBIC, CAIC, AWE)) %>%
tab_spanner(label = "LRTs", columns = c(T11_VLMR_PValue, BLRT_PValue)) %>%
tab_spanner(label = md("Smallest\u00A0Class"), columns = c(Smallest_Class_Combined)) %>%
cols_label(
Grade = "Grade",
Classes = "Classes",
Parameters = md("npar"),
LL = md("*LL*"),
# Perc_Convergence = "% Converged", # Commented out
# Replicated_LL_Perc = "% Replicated", # Commented out
BIC = "BIC",
aBIC = "aBIC",
CAIC = "CAIC",
AWE = "AWE",
T11_VLMR_PValue = "VLMR",
BLRT_PValue = "BLRT",
Entropy = "Entropy",
Smallest_Class_Combined = "n (%)",
BF = "BF",
cmPk = "cmPk"
) %>%
tab_footnote(
footnote = md(
"*Note.* npar = Parameters; *LL* = model log likelihood;
BIC = Bayesian information criterion;
aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion;
AWE = approximate weight of evidence criterion;
BLRT = bootstrapped likelihood ratio test p-value;
VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value;
Smallest n (%) = Number of cases in the smallest class."
),
locations = cells_title()
) %>%
tab_options(column_labels.font.weight = "bold") %>%
fmt_number(
columns = c(LL, BIC, aBIC, CAIC, AWE, Entropy, BF, cmPk),
decimals = 2
) %>%
fmt(
columns = c(T11_VLMR_PValue, BLRT_PValue),
fns = function(x) ifelse(is.na(x), "—", ifelse(x < 0.001, "<.001", scales::number(x, accuracy = .01)))
) %>%
cols_align(align = "center", columns = everything()) %>%
tab_style(
style = list(cell_text(weight = "bold")),
locations = list(
cells_body(columns = BIC, rows = BIC == min(BIC)),
cells_body(columns = aBIC, rows = aBIC == min(aBIC)),
cells_body(columns = CAIC, rows = CAIC == min(CAIC)),
cells_body(columns = AWE, rows = AWE == min(AWE)),
cells_body(
columns = T11_VLMR_PValue,
rows = T11_VLMR_PValue < .05 & lead(T11_VLMR_PValue, default = 1) > .05
),
cells_body(
columns = BLRT_PValue,
rows = BLRT_PValue < .05 & lead(BLRT_PValue, default = 1) > .05
)
)
)
# Store table
fit_tables[[grade]] <- fit_table
# Render table without markdown header
# cat(sprintf("\n### LCA Fit Table for %s Grade\n", toupper(grade))) # Commented out to avoid markdown headers
print(fit_table)
}| Model Fit Summary Table for G7 Grade1 | |||||||||||||
| Grade | Classes | npar | LL |
Model Fit Indices
|
LRTs
|
Entropy |
Smallest Class
|
BF | cmPk | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BIC | aBIC | CAIC | AWE | VLMR | BLRT | n (%) | |||||||
| G7 | 1 | 10 | −11,803.43 | 23,682.28 | 23,650.51 | 23,692.28 | 23,787.70 | — | — | NA | 1886 (100%) | 0.00 | 0.00 |
| G7 | 2 | 21 | −10,418.76 | 20,995.91 | 20,929.19 | 21,016.91 | 21,217.29 | <.001 | <.001 | 0.81 | 782 (41.5%) | 0.00 | 0.00 |
| G7 | 3 | 32 | −10,165.87 | 20,573.10 | 20,471.44 | 20,605.10 | 20,910.45 | 0.00 | <.001 | 0.75 | 384 (20.4%) | 0.00 | 0.00 |
| G7 | 4 | 43 | −10,042.97 | 20,410.26 | 20,273.64 | 20,453.26 | 20,863.57 | 0.00 | <.001 | 0.70 | 390 (20.7%) | 0.00 | 0.00 |
| G7 | 5 | 54 | −9,969.24 | 20,345.76 | 20,174.20 | 20,399.76 | 20,915.04 | 0.04 | <.001 | 0.76 | 175 (9.3%) | 0.00 | 0.00 |
| G7 | 6 | 65 | −9,915.15 | 20,320.54 | 20,114.04 | 20,385.54 | 21,005.78 | 0.01 | <.001 | 0.77 | 180 (9.5%) | 41,346,568.94 | 1.00 |
| G7 | 7 | 76 | −9,891.20 | 20,355.62 | 20,114.16 | 20,431.62 | 21,156.82 | 0.08 | <.001 | 0.77 | 47 (2.5%) | 2,628,029,072.23 | 0.00 |
| G7 | 8 | 87 | −9,871.41 | 20,398.99 | 20,122.60 | 20,485.99 | 21,316.17 | 0.36 | <.001 | 0.75 | 55 (2.9%) | NA | 0.00 |
| 1 Note. npar = Parameters; LL = model log likelihood; BIC = Bayesian information criterion; aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion; BLRT = bootstrapped likelihood ratio test p-value; VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value; Smallest n (%) = Number of cases in the smallest class. | |||||||||||||
| Model Fit Summary Table for G10 Grade1 | |||||||||||||
| Grade | Classes | npar | LL |
Model Fit Indices
|
LRTs
|
Entropy |
Smallest Class
|
BF | cmPk | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BIC | aBIC | CAIC | AWE | VLMR | BLRT | n (%) | |||||||
| G10 | 1 | 10 | −10,072.93 | 20,219.21 | 20,187.44 | 20,229.21 | 20,322.56 | — | — | NA | 1534 (100%) | 0.00 | 0.00 |
| G10 | 2 | 21 | −8,428.38 | 17,010.82 | 16,944.10 | 17,031.82 | 17,227.86 | <.001 | <.001 | 0.86 | 658 (42.9%) | 0.00 | 0.00 |
| G10 | 3 | 32 | −8,067.61 | 16,369.96 | 16,268.31 | 16,401.96 | 16,700.70 | <.001 | <.001 | 0.83 | 297 (19.4%) | 0.00 | 0.00 |
| G10 | 4 | 43 | −7,905.53 | 16,126.50 | 15,989.90 | 16,169.50 | 16,570.93 | <.001 | <.001 | 0.79 | 290 (18.9%) | 0.00 | 0.00 |
| G10 | 5 | 54 | −7,845.44 | 16,087.01 | 15,915.46 | 16,141.01 | 16,645.13 | 0.01 | <.001 | 0.78 | 220 (14.3%) | 6.63 | 0.87 |
| G10 | 6 | 65 | −7,806.99 | 16,090.79 | 15,884.30 | 16,155.79 | 16,762.61 | 0.02 | <.001 | 0.80 | 130 (8.5%) | 529,929.89 | 0.13 |
| G10 | 7 | 76 | −7,779.82 | 16,117.15 | 15,875.72 | 16,193.15 | 16,902.66 | 0.53 | <.001 | 0.85 | 62 (4.1%) | 2,455,890.54 | 0.00 |
| G10 | 8 | 87 | −7,754.19 | 16,146.58 | 15,870.20 | 16,233.58 | 17,045.78 | 0.32 | <.001 | 0.80 | 84 (5.5%) | NA | 0.00 |
| 1 Note. npar = Parameters; LL = model log likelihood; BIC = Bayesian information criterion; aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion; BLRT = bootstrapped likelihood ratio test p-value; VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value; Smallest n (%) = Number of cases in the smallest class. | |||||||||||||
| Model Fit Summary Table for G12 Grade1 | |||||||||||||
| Grade | Classes | npar | LL |
Model Fit Indices
|
LRTs
|
Entropy |
Smallest Class
|
BF | cmPk | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BIC | aBIC | CAIC | AWE | VLMR | BLRT | n (%) | |||||||
| G12 | 1 | 10 | −7,349.13 | 14,768.49 | 14,736.72 | 14,778.49 | 14,868.72 | — | — | NA | 1122 (100%) | 0.00 | 0.00 |
| G12 | 2 | 21 | −5,976.60 | 12,100.68 | 12,033.98 | 12,121.68 | 12,311.16 | <.001 | <.001 | 0.86 | 534 (47.5%) | 0.00 | 0.00 |
| G12 | 3 | 32 | −5,670.60 | 11,565.92 | 11,464.28 | 11,597.92 | 11,886.65 | <.001 | <.001 | 0.85 | 203 (18.1%) | 0.00 | 0.00 |
| G12 | 4 | 43 | −5,543.62 | 11,389.22 | 11,252.64 | 11,432.22 | 11,820.20 | 0.00 | <.001 | 0.80 | 219 (19.5%) | 0.00 | 0.00 |
| G12 | 5 | 54 | −5,483.67 | 11,346.57 | 11,175.06 | 11,400.57 | 11,887.81 | 0.00 | <.001 | 0.84 | 131 (11.7%) | 0.37 | 0.27 |
| G12 | 6 | 65 | −5,444.06 | 11,344.60 | 11,138.14 | 11,409.60 | 11,996.08 | 0.09 | <.001 | 0.84 | 81 (7.2%) | 3,693,185.79 | 0.73 |
| G12 | 7 | 76 | −5,420.55 | 11,374.84 | 11,133.44 | 11,450.84 | 12,136.58 | 0.03 | <.001 | 0.85 | 44 (3.9%) | 810,981.08 | 0.00 |
| G12 | 8 | 87 | −5,395.53 | 11,402.05 | 11,125.72 | 11,489.05 | 12,274.04 | 0.10 | <.001 | 0.84 | 61 (5.4%) | NA | 0.00 |
| 1 Note. npar = Parameters; LL = model log likelihood; BIC = Bayesian information criterion; aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion; BLRT = bootstrapped likelihood ratio test p-value; VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value; Smallest n (%) = Number of cases in the smallest class. | |||||||||||||
Save Fit Tables
# Save tables as PNG files
gtsave(fit_tables[["g7"]], filename = here("tc_lta","figures", "fit_table_lca_g7.png"))
gtsave(fit_tables[["g10"]], filename = here("tc_lta","figures", "fit_table_lca_g10.png"))
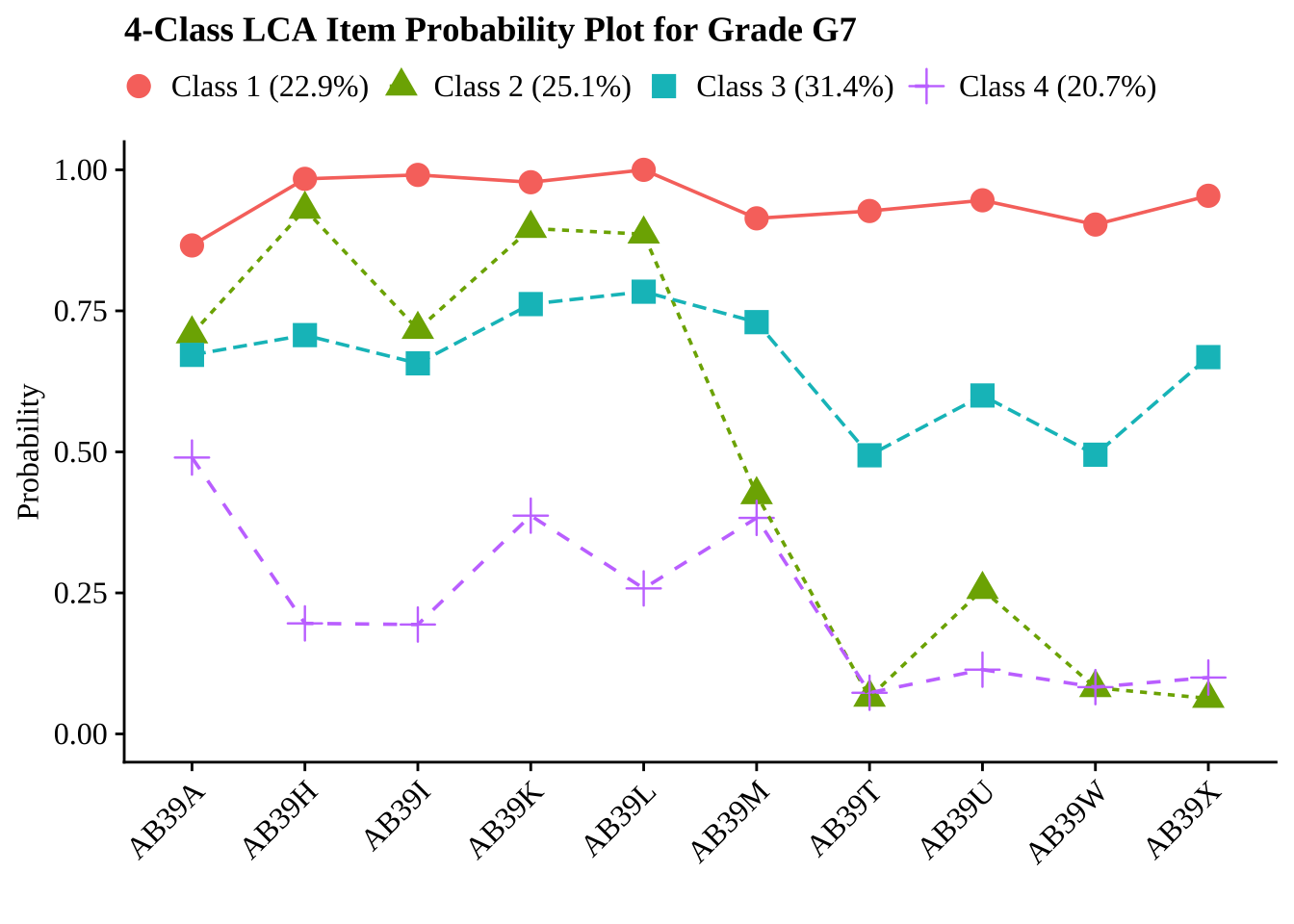
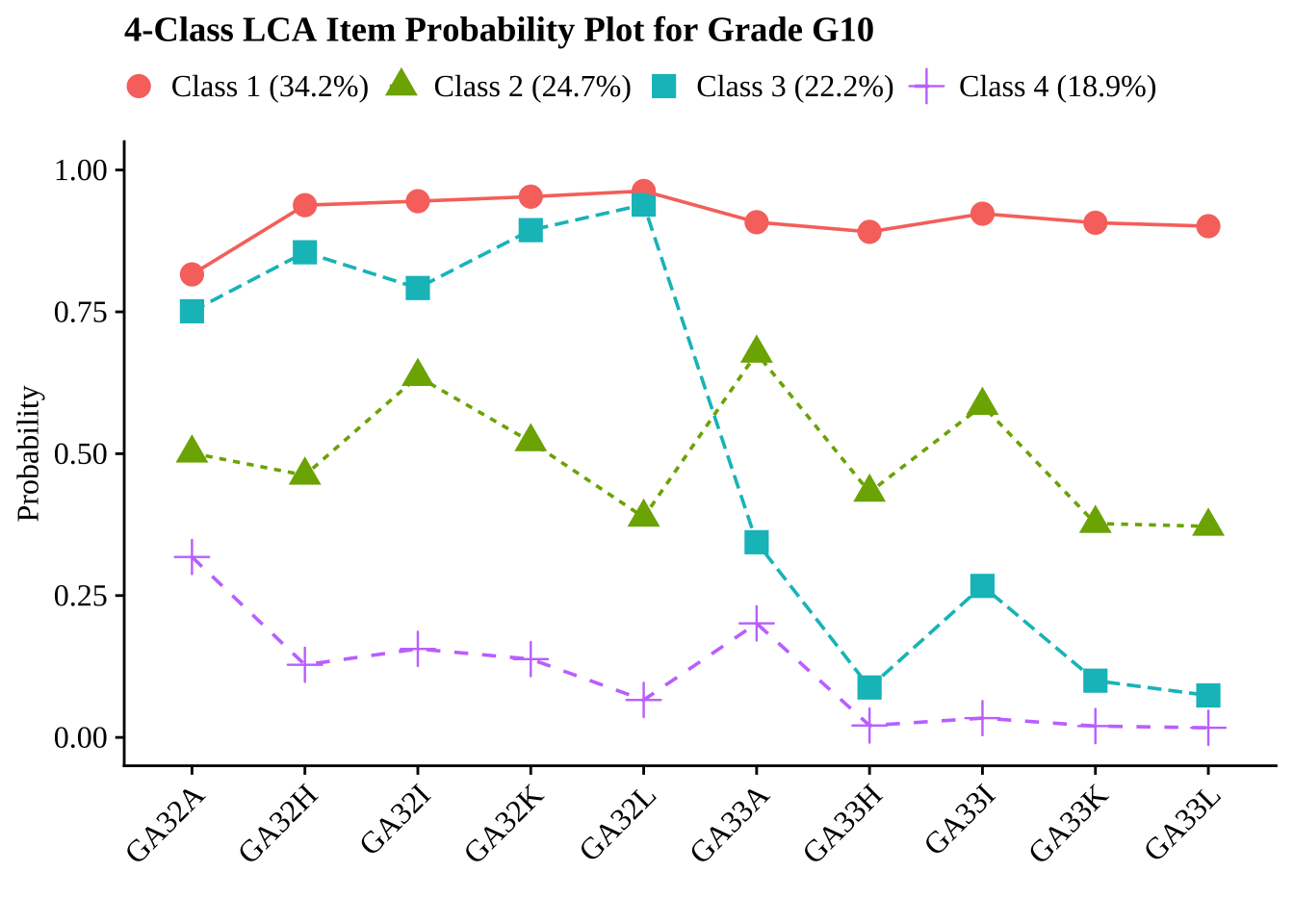
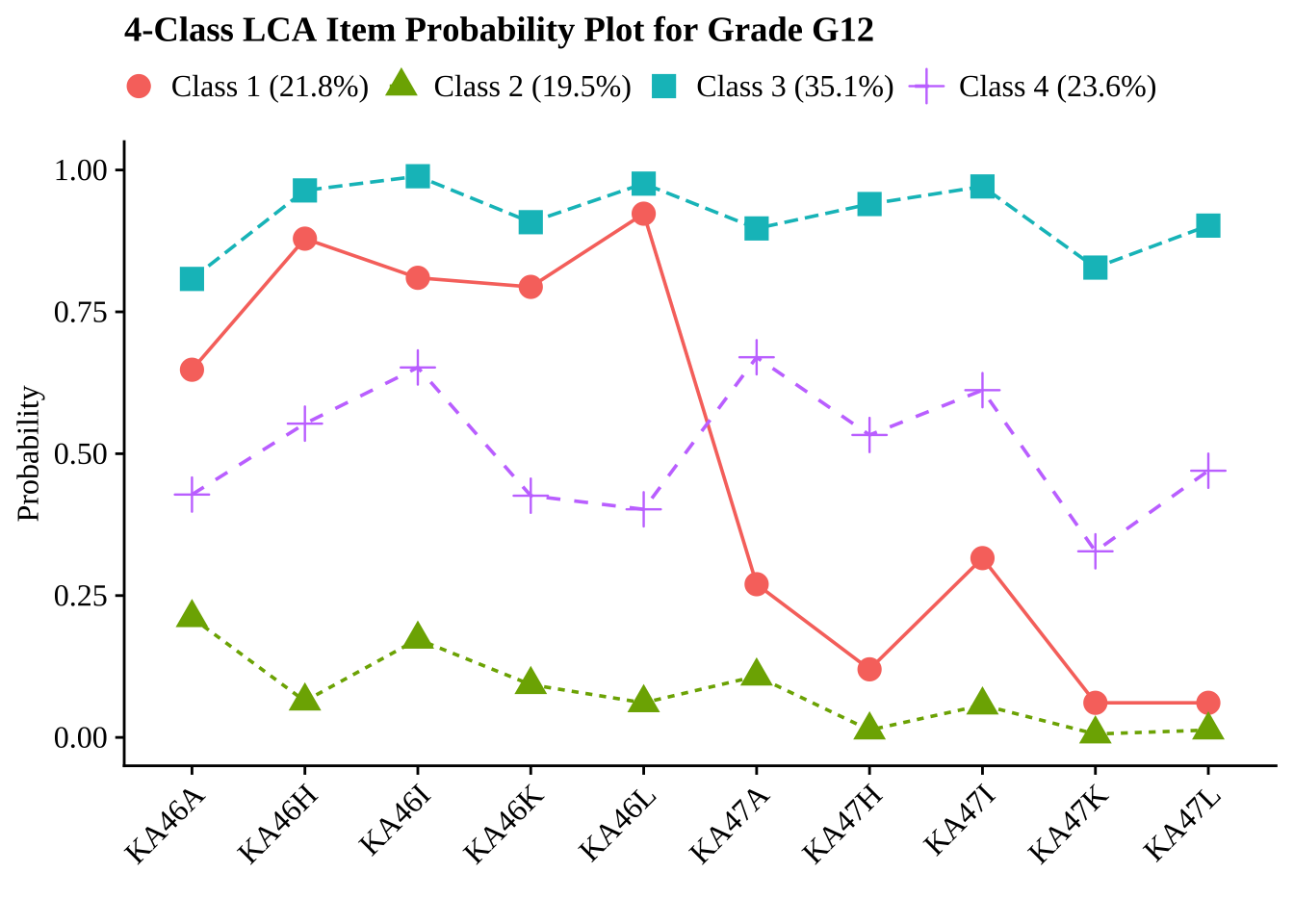
gtsave(fit_tables[["g12"]], filename = here("tc_lta","figures", "fit_table_lca_g12.png"))27.7 Create and Examine Probability Plots for Four Class Solution
To aid in interpretation, we visualize the conditional response probabilities for the selected four-class solution at each grade. These plots show the probability of endorsing each response category within each latent profile and help clarify how the classes
# Source plot_lca function
source(here("tc_lta","functions", "plot_lca.txt"))
# Define grades and folders
grades <- c("g7", "g10", "g12")
folder_paths <- c(
g7 = here("tc_lta","g7_enum"),
g10 = here("tc_lta","g10_enum"),
g12 = here("tc_lta","g12_enum")
)
# Generate plot for each grade
for (grade in grades) {
# Read 4-class model
model_file <- file.path(folder_paths[grade], paste0("c4_", grade, ".out"))
model <- readModels(model_file, quiet = TRUE)
# Base plot
base_plot <- plot_lca(model_name = model)
# Get class sizes and round to 1 decimal
c_size <- round(model$class_counts$modelEstimated$proportion * 100, 1)
# Customize plot with generic class labels
final_plot <- base_plot +
scale_colour_discrete(labels = c(
glue("Class 1 ({c_size[1]}%)"),
glue("Class 2 ({c_size[2]}%)"),
glue("Class 3 ({c_size[3]}%)"),
glue("Class 4 ({c_size[4]}%)")
)) +
scale_shape_discrete(labels = c(
glue("Class 1 ({c_size[1]}%)"),
glue("Class 2 ({c_size[2]}%)"),
glue("Class 3 ({c_size[3]}%)"),
glue("Class 4 ({c_size[4]}%)")
)) +
scale_linetype_discrete(labels = c(
glue("Class 1 ({c_size[1]}%)"),
glue("Class 2 ({c_size[2]}%)"),
glue("Class 3 ({c_size[3]}%)"),
glue("Class 4 ({c_size[4]}%)")
)) +
labs(title = glue("4-Class LCA Item Probability Plot for Grade {toupper(grade)}"))
# Display plot
print(final_plot)
}
27.8 Conduct step 1: Invariant Latent Transition Analysis
In Step 1 of the latent transition analysis (LTA), we estimate an unconditional longitudinal model with measurement invariance across timepoints. This means that item-response thresholds are constrained to be equal across Grades 7, 10, and 12, allowing us to interpret latent class transitions over time on a consistent measurement scale. This step provides the foundation for the 3-step approach by establishing a stable class structure across waves.
# Define LTA model
lta_model <- mplusObject(
TITLE = "4-Class LTA for G7, G10, G12",
VARIABLE = glue(
"categorical = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X
GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L
KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L;
usevar = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X
GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L
KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L
FEMALE MINORITY STEM STEMSUP ENGINEER MATHG8 SCIG8 MATHG11 SCIG11
MATHG7 MATHG10 MATHG12;
auxiliary = FEMALE MINORITY STEM STEMSUP ENGINEER MATHG8 SCIG8 MATHG11 SCIG11
MATHG7 MATHG10 MATHG12;
missing = all(9999);
classes = c1(4) c2(4) c3(4);
auxiliary = stem;"
),
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 500 10;
processors = 4;",
MODEL = glue(
"%overall%
c2 on c1;
c3 on c2;
MODEL c1:
%c1#1%
[AB39A$1-AB39X$1] (1-10);
%c1#2%
[AB39A$1-AB39X$1] (11-20);
%c1#3%
[AB39A$1-AB39X$1] (21-30);
%c1#4%
[AB39A$1-AB39X$1] (31-40);
MODEL c2:
%c2#1%
[GA32A$1-GA33L$1] (1-10);
%c2#2%
[GA32A$1-GA33L$1] (11-20);
%c2#3%
[GA32A$1-GA33L$1] (21-30);
%c2#4%
[GA32A$1-GA33L$1] (31-40);
MODEL c3:
%c3#1%
[KA46A$1-KA47L$1] (1-10);
%c3#2%
[KA46A$1-KA47L$1] (11-20);
%c3#3%
[KA46A$1-KA47L$1] (21-30);
%c3#4%
[KA46A$1-KA47L$1] (31-40);"
),
OUTPUT = "svalues; sampstat; tech11; tech14;",
SAVEDATA = "
file = lta_4class_cprobs.dat;
save = cprobabilities;
missflag = 9999;",
PLOT = "
type = plot3;
series = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X
GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L
KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L (*);",
rdata = lsay_data
)
# Run LTA model
lta_fit <- mplusModeler(
lta_model,
dataout = here("tc_lta","lta_enum", "lsay_lta.dat"),
modelout = here("tc_lta","lta_enum", "lta_4class.inp"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)27.8.1 Plot Invariant Probability Plot
After fitting the invariant LTA model, we examine the conditional response probabilities for each latent class. These plots illustrate how students in each profile tend to respond to the attitudinal items, averaged across timepoints. Because the model assumes measurement invariance, differences between classes can be interpreted consistently across Grades 7, 10, and 12.
# Load LTA model
lta_model <- readModels(here("tc_lta","lta_enum", "lta_4class.out"), quiet = TRUE)
# Define G7 items
g7_items <- c("AB39A", "AB39H", "AB39I", "AB39K", "AB39L", "AB39M", "AB39T", "AB39U", "AB39W", "AB39X")
# Define descriptive item labels (from Table 1 in the paper)
item_labels <- c(
"I enjoy math",
"Math is useful in everyday problems",
"Math helps a person think logically",
"It is important to know math to get a good job",
"I will use math in many ways as an adult",
"I enjoy science",
"Science is useful in everyday problems",
"Science helps a person think logically",
"It is important to know science to get a good job",
"I will use science in many ways as an adult"
)
# Define class names from the paper
class_names <- c(
"Very Positive",
"Qualified Positive",
"Neutral",
"Less Positive"
)
# Inline plot_lta function (with updated title to match Figure 1)
plot_lta <- function(model_name, time_point = "c1", items = NULL) {
probs <- data.frame(model_name$parameters$probability.scale)
pp_plots <- probs %>%
mutate(LatentClass = sub("^", "Class ", LatentClass)) %>%
filter(grepl(paste0("^Class ", toupper(time_point), "#"), LatentClass)) %>%
filter(category == 2) %>%
dplyr::select(est, LatentClass, param)
if (!is.null(items)) {
pp_plots <- pp_plots %>%
filter(param %in% items)
} else {
pp_plots <- pp_plots %>%
filter(param %in% unique(param)[1:10])
}
# Apply class names from the paper
pp_plots <- pp_plots %>%
mutate(LatentClass = case_when(
LatentClass == "Class C1#1" ~ class_names[1],
LatentClass == "Class C1#2" ~ class_names[2],
LatentClass == "Class C1#3" ~ class_names[3],
LatentClass == "Class C1#4" ~ class_names[4],
TRUE ~ LatentClass
))
pp_plots <- pp_plots %>%
pivot_wider(names_from = LatentClass, values_from = est) %>%
relocate(param, .after = last_col())
# Extract class proportions (using Grade 7 proportions from Table 4)
c_size <- data.frame(cs = c(34, 33, 18, 14))
colnames(pp_plots)[1:4] <- paste0(colnames(pp_plots)[1:4], glue(" ({c_size[1:4,]}%)"))
plot_data <- pp_plots %>%
rename("param" = ncol(pp_plots)) %>%
reshape2::melt(id.vars = "param") %>%
mutate(param = fct_inorder(param))
# Apply descriptive item labels
levels(plot_data$param) <- item_labels
# Create the plot with the exact title from Figure 1
p <- plot_data %>%
ggplot(
aes(
x = param,
y = value,
shape = variable,
linetype = variable,
group = variable
)
) +
geom_point(size = 3) +
geom_line() +
scale_shape_manual(values = c(16, 17, 15, 18)) +
scale_linetype_manual(values = c("solid", "dashed", "dotted", "dotdash")) +
scale_color_grey(start = 0.1, end = 0.6) +
scale_x_discrete(labels = function(x) str_wrap(x, width = 15)) +
ylim(0, 1) +
labs(
title = "Proportion of seventh graders endorsing each item by attitudinal profile", # Exact title from Figure 1
x = "",
y = "Probability of Endorsement",
caption = "Note: The four-class structure is invariant across grades 7, 10, and 12, but probabilities and proportions shown are for Grade 7."
) +
theme_classic() +
theme(
text = element_text(family = "serif", size = 12),
legend.text = element_text(family = "serif", size = 12),
legend.key.width = unit(1, "cm"),
legend.title = element_blank(),
legend.position = "top",
axis.text.x = element_text(hjust = 0.5),
plot.margin = margin(b = 40),
plot.caption = element_text(hjust = 0, size = 10, family = "serif"),
plot.title = element_text(size = 12, family = "serif") # Ensure title font matches
)
return(p)
}
# Generate plot using plot_lta
final_plot <- plot_lta(
model_name = lta_model,
time_point = "c1",
items = g7_items
)
# Display plot
print(final_plot)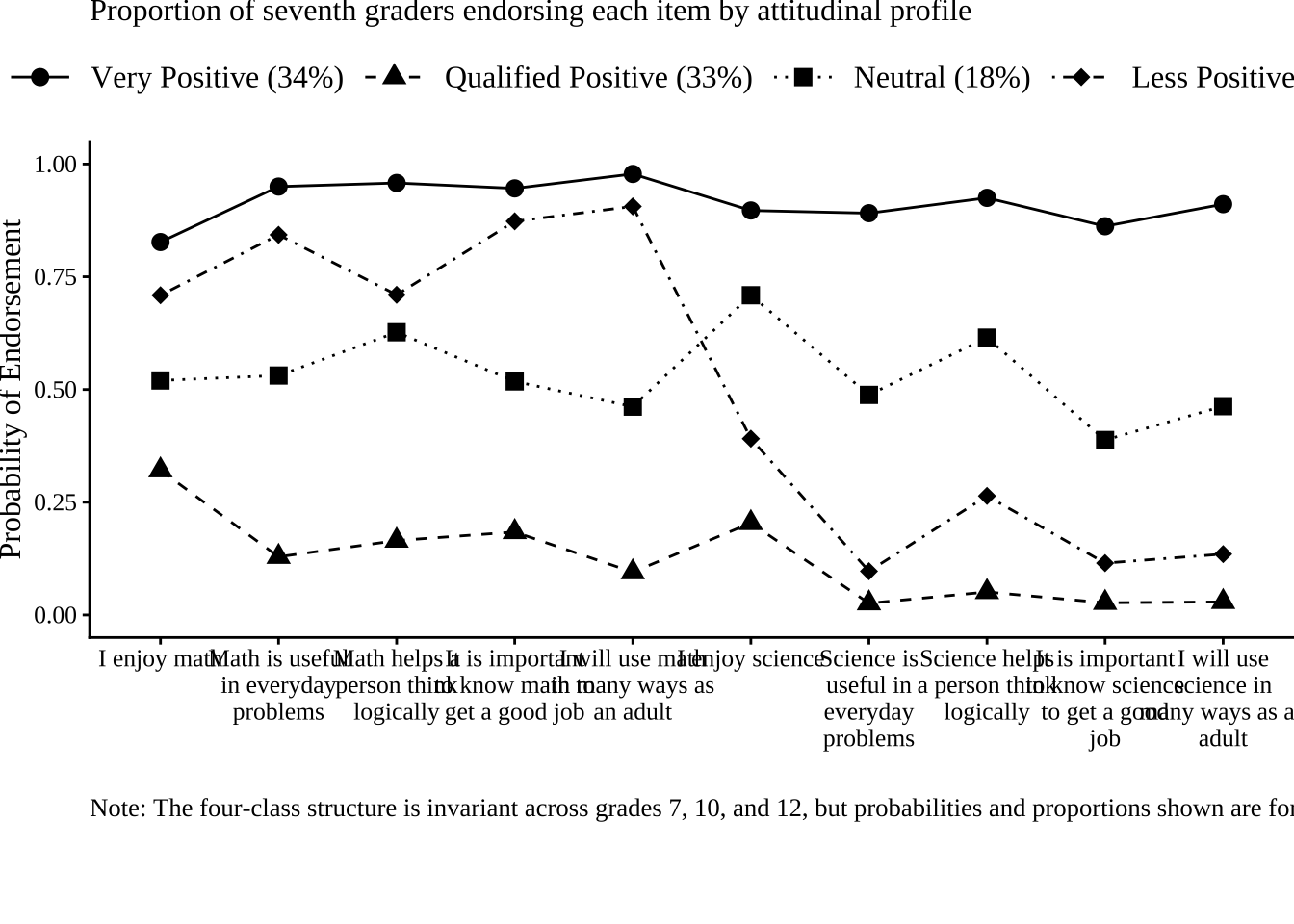
Save Invariant Probability Plot
# Save the final_plot from Chunk 1
ggsave(
filename = here("tc_lta","figures", "LTA_4class_invariant_plot.png"),
plot = final_plot,
dpi = 300,
height = 5,
width = 7,
units = "in"
)27.9 Conduct Step 2 LTA
In Step 2 of the 3-step LTA procedure, we re-estimate the latent class models separately for Grades 7, 10, and 12, this time fixing the item-response thresholds to the logits obtained from the invariant Step 1 model. This ensures that the class measurement remains consistent across time. We also include auxiliary variables to save the modal class assignments for each student at each grade level. These class assignments will be used in Step 3 to estimate covariate and distal outcome effects while accounting for classification uncertainty.
27.9.1 Scrape logits for each grade for the invariant LTA
lta_fit <- readModels(here("tc_lta","lta_enum", "lta_4class.out"))
# Extract item thresholds (logits) for all items across all latent classes
item_logits_full <- lta_fit$parameters$unstandardized %>%
filter(paramHeader == "Thresholds") %>%
filter(str_detect(param, "\\$1")) %>%
select(class = LatentClass, item = param, logit = est)27.9.2 Rerun LCA for Grade 7, 10, and 12 with invariant item probabilities
Run LCA for G7 with fixed item probabilities
lca_belonging_g7 <- {
g7_model <- mplusObject(
TITLE = "4-Class G7 LCA with Fixed Thresholds from Invariant LTA",
VARIABLE = "
categorical = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X;
usevar = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X;
missing = all(9999);
classes = c(4);
auxiliary = GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L
KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L
STEM STEMSup ENGINEER MathG8 SciG8 MathG11 SciG11 Female
Minority MathG7 MathG10 MathG12 CASENUM;",
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 0;
processors = 4;",
MODEL = glue("
%OVERALL%
[c#1@0];
%c#1%
[AB39A$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39A$1']}]
[AB39H$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39H$1']}]
[AB39I$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39I$1']}]
[AB39K$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39K$1']}]
[AB39L$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39L$1']}]
[AB39M$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39M$1']}]
[AB39T$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39T$1']}]
[AB39U$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39U$1']}]
[AB39W$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39W$1']}]
[AB39X$1@{item_logits_full$logit[item_logits_full$class == 'C1#1' & item_logits_full$item == 'AB39X$1']}]
%c#2%
[AB39A$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39A$1']}]
[AB39H$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39H$1']}]
[AB39I$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39I$1']}]
[AB39K$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39K$1']}]
[AB39L$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39L$1']}]
[AB39M$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39M$1']}]
[AB39T$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39T$1']}]
[AB39U$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39U$1']}]
[AB39W$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39W$1']}]
[AB39X$1@{item_logits_full$logit[item_logits_full$class == 'C1#2' & item_logits_full$item == 'AB39X$1']}]
%c#3%
[AB39A$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39A$1']}]
[AB39H$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39H$1']}]
[AB39I$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39I$1']}]
[AB39K$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39K$1']}]
[AB39L$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39L$1']}]
[AB39M$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39M$1']}]
[AB39T$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39T$1']}]
[AB39U$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39U$1']}]
[AB39W$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39W$1']}]
[AB39X$1@{item_logits_full$logit[item_logits_full$class == 'C1#3' & item_logits_full$item == 'AB39X$1']}]
%c#4%
[AB39A$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39A$1']}]
[AB39H$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39H$1']}]
[AB39I$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39I$1']}]
[AB39K$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39K$1']}]
[AB39L$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39L$1']}]
[AB39M$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39M$1']}]
[AB39T$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39T$1']}]
[AB39U$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39U$1']}]
[AB39W$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39W$1']}]
[AB39X$1@{item_logits_full$logit[item_logits_full$class == 'C1#4' & item_logits_full$item == 'AB39X$1']}]
"),
OUTPUT = "
sampstat;
tech1;
tech11;
tech14;
svalues;",
SAVEDATA = "
file = g7.dat;
save = cprobabilities;
missflag = 9999;",
rdata = lsay_data
)
mplusModeler(
g7_model,
dataout = here("tc_lta","lca_enum2", "lca_g7.dat"),
modelout = here("tc_lta","lca_enum2", "lca_g7.inp"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
}Run LCA for G10 with fixed item probabilities
lca_belonging_g10 <- {
g10_model <- mplusObject(
TITLE = "4-Class G10 LCA with Fixed Thresholds from Invariant LTA",
VARIABLE = "
categorical = GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L;
usevar = GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L;
auxiliary = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X
KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L
STEM STEMSup ENGINEER MathG8 SciG8 MathG11 SciG11 Female
Minority MathG7 MathG10 MathG12 CASENUM;
missing = all(9999);
classes = c(4);",
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 0;
processors = 4;",
MODEL = glue("
%OVERALL%
[c#1@0];
%c#1%
[GA32A$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA32A$1']}]
[GA32H$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA32H$1']}]
[GA32I$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA32I$1']}]
[GA32K$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA32K$1']}]
[GA32L$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA32L$1']}]
[GA33A$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA33A$1']}]
[GA33H$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA33H$1']}]
[GA33I$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA33I$1']}]
[GA33K$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA33K$1']}]
[GA33L$1@{item_logits_full$logit[item_logits_full$class == 'C2#1' & item_logits_full$item == 'GA33L$1']}]
%c#2%
[GA32A$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA32A$1']}]
[GA32H$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA32H$1']}]
[GA32I$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA32I$1']}]
[GA32K$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA32K$1']}]
[GA32L$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA32L$1']}]
[GA33A$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA33A$1']}]
[GA33H$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA33H$1']}]
[GA33I$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA33I$1']}]
[GA33K$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA33K$1']}]
[GA33L$1@{item_logits_full$logit[item_logits_full$class == 'C2#2' & item_logits_full$item == 'GA33L$1']}]
%c#3%
[GA32A$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA32A$1']}]
[GA32H$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA32H$1']}]
[GA32I$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA32I$1']}]
[GA32K$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA32K$1']}]
[GA32L$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA32L$1']}]
[GA33A$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA33A$1']}]
[GA33H$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA33H$1']}]
[GA33I$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA33I$1']}]
[GA33K$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA33K$1']}]
[GA33L$1@{item_logits_full$logit[item_logits_full$class == 'C2#3' & item_logits_full$item == 'GA33L$1']}]
%c#4%
[GA32A$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA32A$1']}]
[GA32H$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA32H$1']}]
[GA32I$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA32I$1']}]
[GA32K$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA32K$1']}]
[GA32L$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA32L$1']}]
[GA33A$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA33A$1']}]
[GA33H$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA33H$1']}]
[GA33I$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA33I$1']}]
[GA33K$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA33K$1']}]
[GA33L$1@{item_logits_full$logit[item_logits_full$class == 'C2#4' & item_logits_full$item == 'GA33L$1']}]
"),
OUTPUT = "
sampstat;
tech1;
tech11;
tech14;
svalues;",
SAVEDATA = "
file = g10.dat;
save = cprob;
missflag = 9999;",
rdata = lsay_data
)
mplusModeler(
g10_model,
dataout = here("tc_lta","lca_enum2", "lca_g10.dat"),
modelout = here("tc_lta","lca_enum2", "lca_g10.inp"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
}Run LCA for G12 with fixed item probabilities
lca_belonging_g12 <- {
g12_model <- mplusObject(
TITLE = "4-Class G12 LCA with Fixed Thresholds from Invariant LTA",
VARIABLE = "
categorical = KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L;
usevar = KA46A KA46H KA46I KA46K KA46L KA47A KA47H KA47I KA47K KA47L;
auxiliary = AB39A AB39H AB39I AB39K AB39L AB39M AB39T AB39U AB39W AB39X
GA32A GA32H GA32I GA32K GA32L GA33A GA33H GA33I GA33K GA33L
STEM STEMSup ENGINEER MathG8 SciG8 MathG11 SciG11 Female
Minority MathG7 MathG10 MathG12 CASENUM;
missing = all(9999);
classes = c(4);",
ANALYSIS = "
estimator = mlr;
type = mixture;
starts = 0;
processors = 4;",
MODEL = glue("
%OVERALL%
[c#1@0];
%c#1%
[KA46A$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA46A$1']}]
[KA46H$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA46H$1']}]
[KA46I$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA46I$1']}]
[KA46K$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA46K$1']}]
[KA46L$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA46L$1']}]
[KA47A$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA47A$1']}]
[KA47H$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA47H$1']}]
[KA47I$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA47I$1']}]
[KA47K$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA47K$1']}]
[KA47L$1@{item_logits_full$logit[item_logits_full$class == 'C3#1' & item_logits_full$item == 'KA47L$1']}]
%c#2%
[KA46A$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA46A$1']}]
[KA46H$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA46H$1']}]
[KA46I$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA46I$1']}]
[KA46K$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA46K$1']}]
[KA46L$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA46L$1']}]
[KA47A$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA47A$1']}]
[KA47H$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA47H$1']}]
[KA47I$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA47I$1']}]
[KA47K$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA47K$1']}]
[KA47L$1@{item_logits_full$logit[item_logits_full$class == 'C3#2' & item_logits_full$item == 'KA47L$1']}]
%c#3%
[KA46A$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA46A$1']}]
[KA46H$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA46H$1']}]
[KA46I$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA46I$1']}]
[KA46K$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA46K$1']}]
[KA46L$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA46L$1']}]
[KA47A$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA47A$1']}]
[KA47H$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA47H$1']}]
[KA47I$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA47I$1']}]
[KA47K$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA47K$1']}]
[KA47L$1@{item_logits_full$logit[item_logits_full$class == 'C3#3' & item_logits_full$item == 'KA47L$1']}]
%c#4%
[KA46A$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA46A$1']}]
[KA46H$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA46H$1']}]
[KA46I$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA46I$1']}]
[KA46K$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA46K$1']}]
[KA46L$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA46L$1']}]
[KA47A$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA47A$1']}]
[KA47H$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA47H$1']}]
[KA47I$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA47I$1']}]
[KA47K$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA47K$1']}]
[KA47L$1@{item_logits_full$logit[item_logits_full$class == 'C3#4' & item_logits_full$item == 'KA47L$1']}]
"),
OUTPUT = "
sampstat;
tech1;
tech11;
tech14;
svalues;",
SAVEDATA = "
file = g12.dat;
save = cprob;
missflag = 9999;",
rdata = lsay_data
)
mplusModeler(
g12_model,
dataout = here("tc_lta","lca_enum2", "lca_g12.dat"),
modelout = here("tc_lta","lca_enum2", "lca_g12.inp"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)
}27.9.3 Prepare data for Step 2 LTA
# Helper: extract variable names from a .out file
scrape_saved_vars <- function(out_path) {
lines <- readLines(out_path)
start <- grep("^SAVEDATA INFORMATION$", lines)
section <- lines[start:length(lines)]
var_start <- grep("^\\s*Order and format of variables\\s*$", section)
var_lines <- section[(var_start + 1):length(section)]
end_idx <- which(grepl("^\\s*Save file format\\s*$", var_lines))[1]
if (!is.na(end_idx)) {
var_lines <- var_lines[1:(end_idx - 1)]
}
var_lines <- var_lines[grepl("^\\s*[A-Za-z0-9_]+\\s+F10\\.3\\s*$", var_lines)]
trimws(gsub("\\s+F10\\.3\\s*$", "", var_lines))
}
# Paths
g7_path <- here("tc_lta","lca_enum2", "g7.dat")
g10_path <- here("tc_lta","lca_enum2", "g10.dat")
g12_path <- here("tc_lta","lca_enum2", "g12.dat")
# Output files
g7_out <- here("tc_lta","lca_enum2", "lca_g7.out")
g10_out <- here("tc_lta","lca_enum2", "lca_g10.out")
g12_out <- here("tc_lta","lca_enum2", "lca_g12.out")
# Scrape column names
g7_vars <- scrape_saved_vars(g7_out)
g10_vars <- scrape_saved_vars(g10_out)
g12_vars <- scrape_saved_vars(g12_out)
# Read and rename C column
g7 <- read.table(g7_path, col.names = g7_vars)
g10 <- read.table(g10_path, col.names = g10_vars)
g12 <- read.table(g12_path, col.names = g12_vars)
# Rename C columns
g7 <- g7 %>% rename(N1 = C)
g10 <- g10 %>% rename(N2 = C)
g12 <- g12 %>% rename(N3 = C)
# Write to CSV for inspection
write_csv(g7, here("tc_lta","lca_enum2", "g7_named.csv"))
write_csv(g10, here("tc_lta","lca_enum2", "g10_named.csv"))
write_csv(g12, here("tc_lta","lca_enum2", "g12_named.csv"))27.10 Merge Files
# Load base file
g7 <- read_csv(here("tc_lta","lca_enum2", "g7_named.csv"), col_types = cols())
# Only grab CASENUM + N2 / N3 from others
g10 <- read_csv(here("tc_lta","lca_enum2", "g10_named.csv"), col_types = cols()) %>% select(CASENUM, N2)
g12 <- read_csv(here("tc_lta","lca_enum2", "g12_named.csv"), col_types = cols()) %>% select(CASENUM, N3)
# After loading all three CSVs:
g7 <- g7 %>% mutate(across(everything(), ~replace_na(.x, 9999)))
g10 <- g10 %>% mutate(across(everything(), ~replace_na(.x, 9999)))
g12 <- g12 %>% mutate(across(everything(), ~replace_na(.x, 9999)))
# Merge cleanly by CASENUM
merged <- g7 %>%
left_join(g10, by = "CASENUM") %>%
left_join(g12, by = "CASENUM") %>%
mutate(
N1 = replace_na(N1, 9999),
N2 = replace_na(N2, 9999),
N3 = replace_na(N3, 9999)
)
# Write final output
write_csv(merged, here("tc_lta","lca_enum2", "merged.csv"))27.10.1 Scrape Logits for LTA
g7_model <- readModels(here("tc_lta","lca_enum2", "lca_g7.out"))
g10_model <- readModels(here("tc_lta","lca_enum2", "lca_g10.out"))
g12_model <- readModels(here("tc_lta","lca_enum2", "lca_g12.out"))27.10.2 Extract Logits
# Model list using correct source: class_counts$logitProbs.mostLikely
model_list <- list(
G7 = g7_model$class_counts$logitProbs.mostLikely,
G10 = g10_model$class_counts$logitProbs.mostLikely,
G12 = g12_model$class_counts$logitProbs.mostLikely
)
# Reshape each 4x4 matrix into tidy long format
step2_logits <- map2_dfr(
model_list,
names(model_list),
function(mat, grade) {
# Assign column names explicitly
colnames(mat) <- paste0("V", seq_len(ncol(mat)))
as.data.frame(mat) %>%
mutate(source_class = row_number()) %>%
pivot_longer(
cols = starts_with("V"),
names_to = "assigned_class",
names_prefix = "V",
values_to = "logit"
) %>%
mutate(
assigned_class = as.integer(assigned_class),
grade = grade
) %>%
select(grade, source_class, assigned_class, logit)
}
)27.10.3 Conduct Step 2 LTA with fixed classes
After rerunning the grade-specific LCAs with fixed logits, we merge the saved modal class assignment files into a single dataset. This merged file includes class membership at each grade along with relevant auxiliary variables. Using this file, we then run the Step 2 LTA model by fixing the class assignment logits (classification probabilities) from the grade-specific models. This step allows us to model transitions across latent profiles over time while incorporating the uncertainty in class membership derived from the classification error rates.
As a quality check, we cross-reference the estimated class sizes from Step 2 against those from the invariant Step 1 model. Matching class sizes confirms that the Step 2 specification correctly replicates the measurement structure and preserves consistency in profile estimation.
# Extract logits for each timepoint into matrices
logits_n1 <- matrix(step2_logits$logit[step2_logits$grade == "G7"], nrow = 4, byrow = TRUE)
logits_n2 <- matrix(step2_logits$logit[step2_logits$grade == "G10"], nrow = 4, byrow = TRUE)
logits_n3 <- matrix(step2_logits$logit[step2_logits$grade == "G12"], nrow = 4, byrow = TRUE)
# Build Mplus object
step2_lta_model <- mplusObject(
TITLE = "Step 2 LTA with Fixed Logits — No Covariates",
VARIABLE = "
USEVAR = n1 n2 n3;
NOMINAL = n1 n2 n3;
MISSING = all(9999);
CLASSES = c1(4) c2(4) c3(4);",
ANALYSIS = "
TYPE = mixture;
STARTS = 0;",
MODEL = glue("
MODEL c1:
%c1#1%
[n1#1@{logits_n1[1,1]}];
[n1#2@{logits_n1[1,2]}];
[n1#3@{logits_n1[1,3]}];
%c1#2%
[n1#1@{logits_n1[2,1]}];
[n1#2@{logits_n1[2,2]}];
[n1#3@{logits_n1[2,3]}];
%c1#3%
[n1#1@{logits_n1[3,1]}];
[n1#2@{logits_n1[3,2]}];
[n1#3@{logits_n1[3,3]}];
%c1#4%
[n1#1@{logits_n1[4,1]}];
[n1#2@{logits_n1[4,2]}];
[n1#3@{logits_n1[4,3]}];
MODEL c2:
%c2#1%
[n2#1@{logits_n2[1,1]}];
[n2#2@{logits_n2[1,2]}];
[n2#3@{logits_n2[1,3]}];
%c2#2%
[n2#1@{logits_n2[2,1]}];
[n2#2@{logits_n2[2,2]}];
[n2#3@{logits_n2[2,3]}];
%c2#3%
[n2#1@{logits_n2[3,1]}];
[n2#2@{logits_n2[3,2]}];
[n2#3@{logits_n2[3,3]}];
%c2#4%
[n2#1@{logits_n2[4,1]}];
[n2#2@{logits_n2[4,2]}];
[n2#3@{logits_n2[4,3]}];
MODEL c3:
%c3#1%
[n3#1@{logits_n3[1,1]}];
[n3#2@{logits_n3[1,2]}];
[n3#3@{logits_n3[1,3]}];
%c3#2%
[n3#1@{logits_n3[2,1]}];
[n3#2@{logits_n3[2,2]}];
[n3#3@{logits_n3[2,3]}];
%c3#3%
[n3#1@{logits_n3[3,1]}];
[n3#2@{logits_n3[3,2]}];
[n3#3@{logits_n3[3,3]}];
%c3#4%
[n3#1@{logits_n3[4,1]}];
[n3#2@{logits_n3[4,2]}];
[n3#3@{logits_n3[4,3]}];
"),
OUTPUT = "svalues; tech11; tech14;",
rdata = merged
)
# Run model
step2_lta_fit <- mplusModeler(
step2_lta_model,
modelout = here("tc_lta","lta_enum", "step2_lta.inp"),
dataout = here("tc_lta","lta_enum", "step2_lta.dat"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)27.11 Run Step 3 LTA with Covariates
In Step 3, we estimate the full LTA model with covariates using the merged dataset from Step 2. This step regresses latent class membership and class transitions on external variables (e.g., gender, race/ethnicity, or prior achievement) to examine how background characteristics predict profile membership and change over time. Because classification error was accounted for in Step 2, the resulting covariate estimates are unbiased and reflect the true relationships between predictors and latent trajectories.
# Build Mplus object
step3_lta_model <- mplusObject(
TITLE = "Step 3 LTA with Fixed Logits and Covariates",
VARIABLE = "
USEVAR = n1 n2 n3 Female Minority MathG7 MathG10 MathG12;
NOMINAL = n1 n2 n3;
MISSING = all(9999);
CLASSES = c1(4) c2(4) c3(4);",
ANALYSIS = "
TYPE = mixture;
STARTS = 0;",
MODEL = glue("
%OVERALL%
c1 ON Minority Female (c11f c12f c13f) MathG7;
c2 ON c1 Minority Female MathG10;
c3 ON c2 Minority Female MathG12;
MODEL c1:
%c1#1%
[n1#1@{logits_n1[1,1]}];
[n1#2@{logits_n1[1,2]}];
[n1#3@{logits_n1[1,3]}];
%c1#2%
[n1#1@{logits_n1[2,1]}];
[n1#2@{logits_n1[2,2]}];
[n1#3@{logits_n1[2,3]}];
%c1#3%
[n1#1@{logits_n1[3,1]}];
[n1#2@{logits_n1[3,2]}];
[n1#3@{logits_n1[3,3]}];
%c1#4%
[n1#1@{logits_n1[4,1]}];
[n1#2@{logits_n1[4,2]}];
[n1#3@{logits_n1[4,3]}];
MODEL c2:
%c2#1%
[n2#1@{logits_n2[1,1]}];
[n2#2@{logits_n2[1,2]}];
[n2#3@{logits_n2[1,3]}];
%c2#2%
[n2#1@{logits_n2[2,1]}];
[n2#2@{logits_n2[2,2]}];
[n2#3@{logits_n2[2,3]}];
%c2#3%
[n2#1@{logits_n2[3,1]}];
[n2#2@{logits_n2[3,2]}];
[n2#3@{logits_n2[3,3]}];
%c2#4%
[n2#1@{logits_n2[4,1]}];
[n2#2@{logits_n2[4,2]}];
[n2#3@{logits_n2[4,3]}];
MODEL c3:
%c3#1%
[n3#1@{logits_n3[1,1]}];
[n3#2@{logits_n3[1,2]}];
[n3#3@{logits_n3[1,3]}];
%c3#2%
[n3#1@{logits_n3[2,1]}];
[n3#2@{logits_n3[2,2]}];
[n3#3@{logits_n3[2,3]}];
%c3#3%
[n3#1@{logits_n3[3,1]}];
[n3#2@{logits_n3[3,2]}];
[n3#3@{logits_n3[3,3]}];
%c3#4%
[n3#1@{logits_n3[4,1]}];
[n3#2@{logits_n3[4,2]}];
[n3#3@{logits_n3[4,3]}];
"),
OUTPUT = "svalues; tech11; tech14;",
rdata = merged
)
# Run model
step3_lta_fit <- mplusModeler(
step3_lta_model,
modelout = here("tc_lta","lta_enum", "step3_lta.inp"),
dataout = here("tc_lta","lta_enum", "step3_lta.dat"),
check = TRUE,
run = TRUE,
hashfilename = FALSE
)27.12 Create Transition Probability Plots
To explore how students’ attitudinal profiles evolve over time, we generated transition probability plots using Sankey diagrams. We began with the full sample, then created subgroup-specific plots to highlight potential differences by gender and racial/ethnic identity. Specifically, we examined transitions for female students, male students, female students from minoritized backgrounds, and female students who are not part of a racial/ethnic minority. These visualizations help illustrate which profiles are most stable and where notable shifts occur across grades.
Re order classes
merged <- merged %>%
mutate(
# Recode N1 (Grade 7)
N1_label = case_when(
N1 == 1 ~ "Very Positive",
N1 == 4 ~ "Qualified Positive",
N1 == 3 ~ "Neutral",
N1 == 2 ~ "Less Positive"
),
# Recode N2 (Grade 10)
N2_label = case_when(
N2 == 1 ~ "Very Positive",
N2 == 4 ~ "Qualified Positive",
N2 == 3 ~ "Neutral",
N2 == 2 ~ "Less Positive"
),
# Recode N3 (Grade 12)
N3_label = case_when(
N3 == 1 ~ "Very Positive",
N3 == 4 ~ "Qualified Positive",
N3 == 3 ~ "Neutral",
N3 == 2 ~ "Less Positive"
),
# Factorize with correct top-down plotting order
N1_label = factor(N1_label, levels = c(
"Very Positive", "Qualified Positive", "Neutral", "Less Positive"
)),
N2_label = factor(N2_label, levels = c(
"Very Positive", "Qualified Positive", "Neutral", "Less Positive"
)),
N3_label = factor(N3_label, levels = c(
"Very Positive", "Qualified Positive", "Neutral", "Less Positive"
))
)27.12.1 Examine Transition Probability Plot for the Full Sample
#### 1. Reload transition function and read model ####
source(here("tc_lta", "functions", "plot_transitions_function.R"))
step3_full <- readModels(here::here("tc_lta","lta_enum", "step3_lta.out"))
#### 2. Define color palette (new correct labels) ####
class_colors <- c(
"Very Positive" = "#BA68C8",
"Qualified Positive" = "#00BCD4",
"Neutral" = "#8BC34A",
"Less Positive" = "#E74C3C"
)
#### 3. Set correct class names per quadrant (TL → TR → BL → BR) ####
plot_full <- plot_transitions_function(
model_name = step3_full,
color_palette = class_colors,
facet_labels = c(
`1` = "Very Positive",
`2` = "Qualified Positive",
`3` = "Neutral",
`4` = "Less Positive"
),
timepoint_labels = c(
`1` = "Grade 7",
`2` = "Grade 10",
`3` = "Grade 12"
),
class_labels = names(class_colors)
)
#### 4. Add single plot title and theme settings ####
plot_full <- plot_full +
ggtitle("Attitudinal Profile Transitions: Grade 7 to 10 and Grade 10 to 12") +
theme(
strip.text = element_text(
family = "Arial",
size = 11,
face = "plain"
),
plot.title = element_text(
family = "Arial",
hjust = 0.5,
size = 14,
margin = margin(b = 10)
),
text = element_text(family = "Arial")
)
#### 5. Render plot ####
plot_full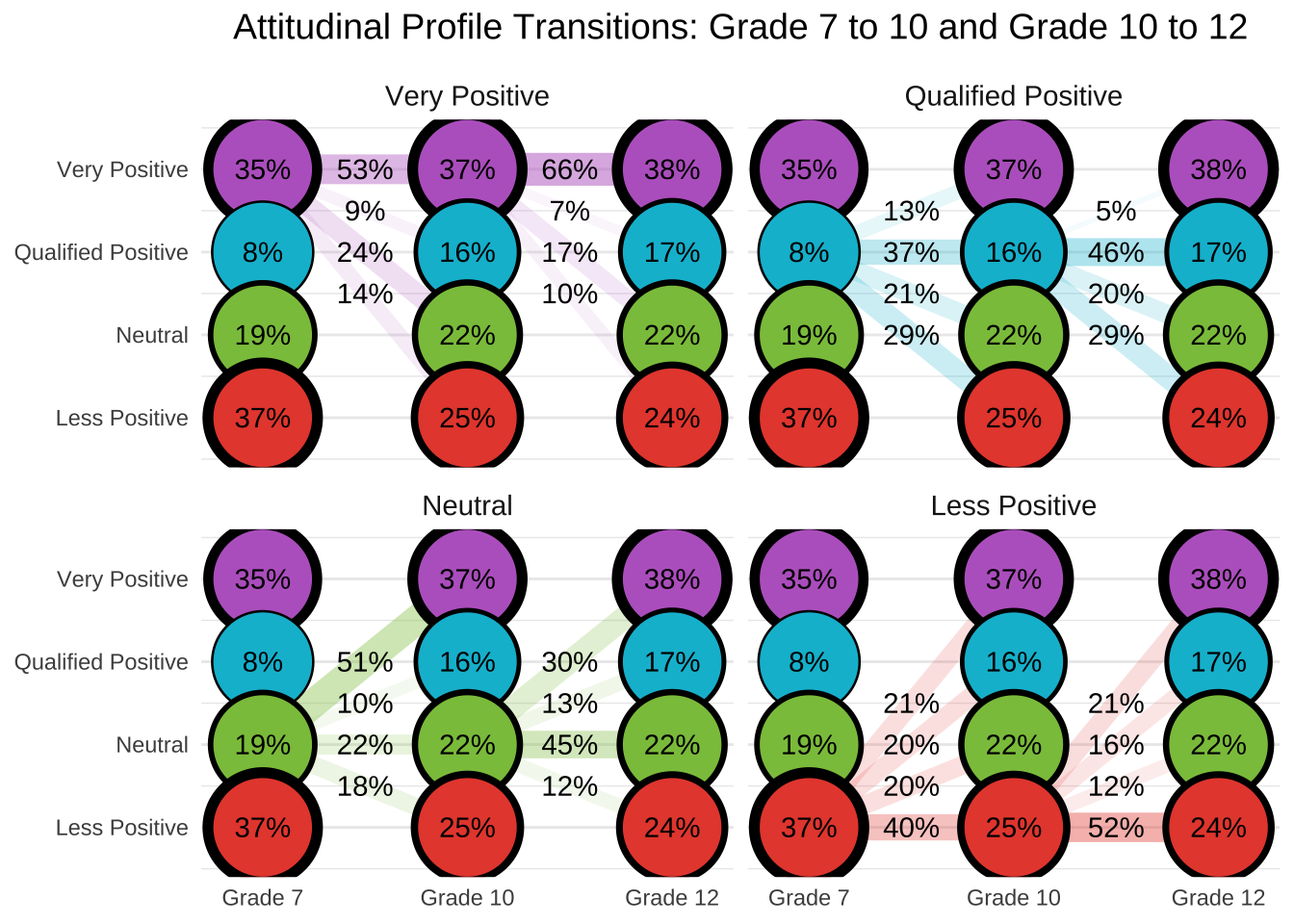
27.12.2 Examine Transition Probability Plot for Females
source(here("tc_lta", "functions", "make_transition_object.R"))
merged_female <- merged %>%
filter(FEMALE == 1)
#### 2. Build Mplus-style transition object from modal assignments ####
female_obj <- make_transition_object(merged_female, "N1", "N2", "N3")
#### 3. Create plot with updated facet labels and font ####
plot_female <- plot_transitions_function(
model_name = female_obj,
color_palette = class_colors,
facet_labels = c(
`1` = "Very Positive",
`2` = "Qualified Positive",
`3` = "Neutral",
`4` = "Less Positive"
),
timepoint_labels = c(
`1` = "Grade 7",
`2` = "Grade 10",
`3` = "Grade 12"
),
class_labels = names(class_colors)
) +
ggtitle("Attitudinal Profile Transitions\nFemale Students: Grade 7 to 10 and Grade 10 to 12") +
theme(
strip.text = element_text(
family = "Arial",
size = 11,
face = "plain"
),
plot.title = element_text(
family = "Arial",
hjust = 0.5,
size = 14,
margin = margin(b = 10)
),
text = element_text(family = "Arial")
)
#### 4. Display plot ####
plot_female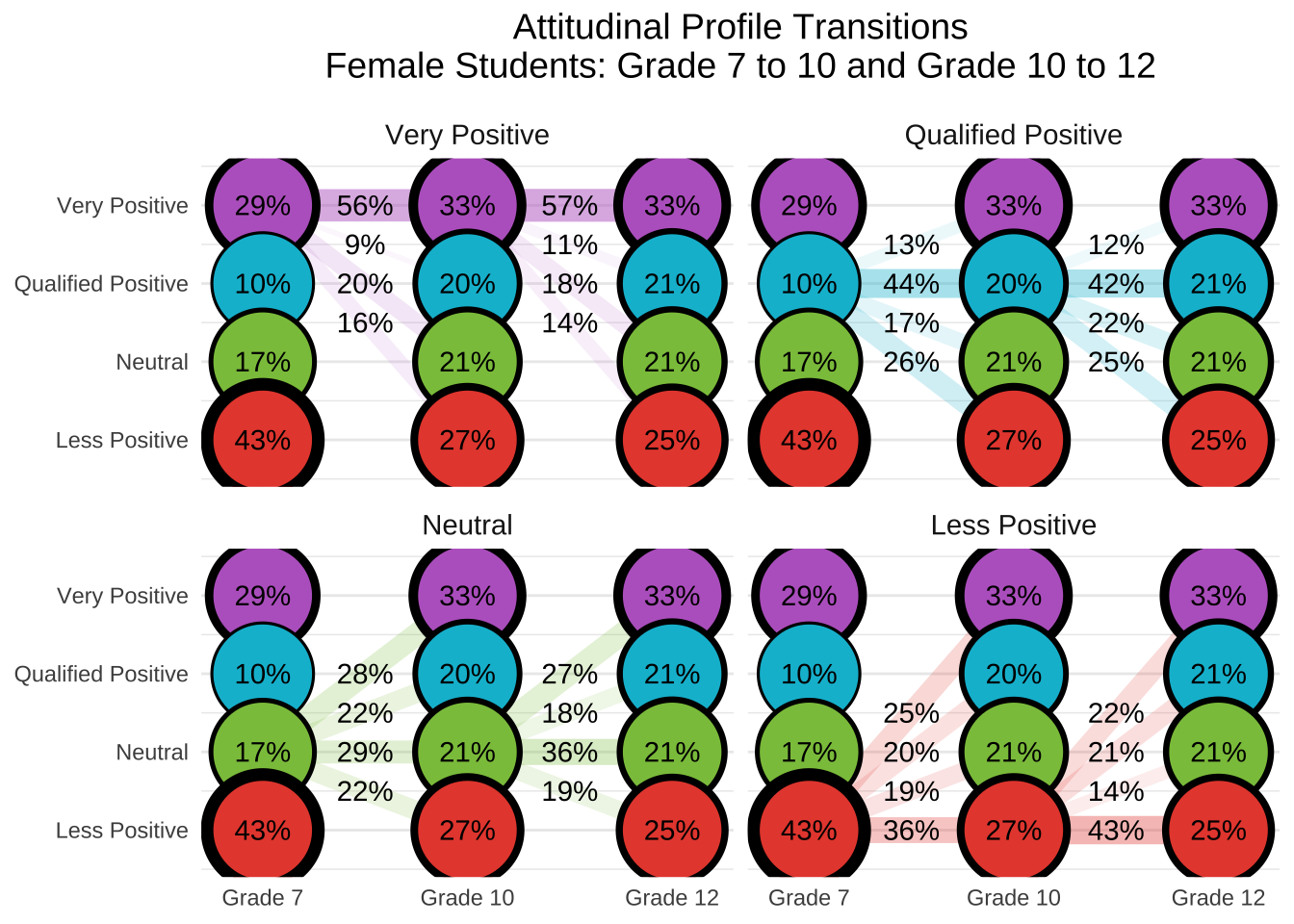
Save Female plots
27.12.3 Examine Transition Probability Plot for Males
merged_male <- merged %>%
filter(FEMALE == 0)
#### 2. Build Mplus-style transition object from modal assignments ####
male_obj <- make_transition_object(merged_male, "N1", "N2", "N3")
#### 3. Create plot with updated facet labels and font ####
plot_male <- plot_transitions_function(
model_name = male_obj,
color_palette = class_colors,
facet_labels = c(
`1` = "Very Positive",
`2` = "Qualified Positive",
`3` = "Neutral",
`4` = "Less Positive"
),
timepoint_labels = c(
`1` = "Grade 7",
`2` = "Grade 10",
`3` = "Grade 12"
),
class_labels = names(class_colors)
) +
ggtitle("Attitudinal Profile Transitions\nMale Students: Grade 7 to 10 and Grade 10 to 12") +
theme(
strip.text = element_text(
family = "Arial",
size = 11,
face = "plain"
),
plot.title = element_text(
family = "Arial",
hjust = 0.5,
size = 14,
margin = margin(b = 10)
),
text = element_text(family = "Arial")
)
#### 4. Display plot ####
plot_male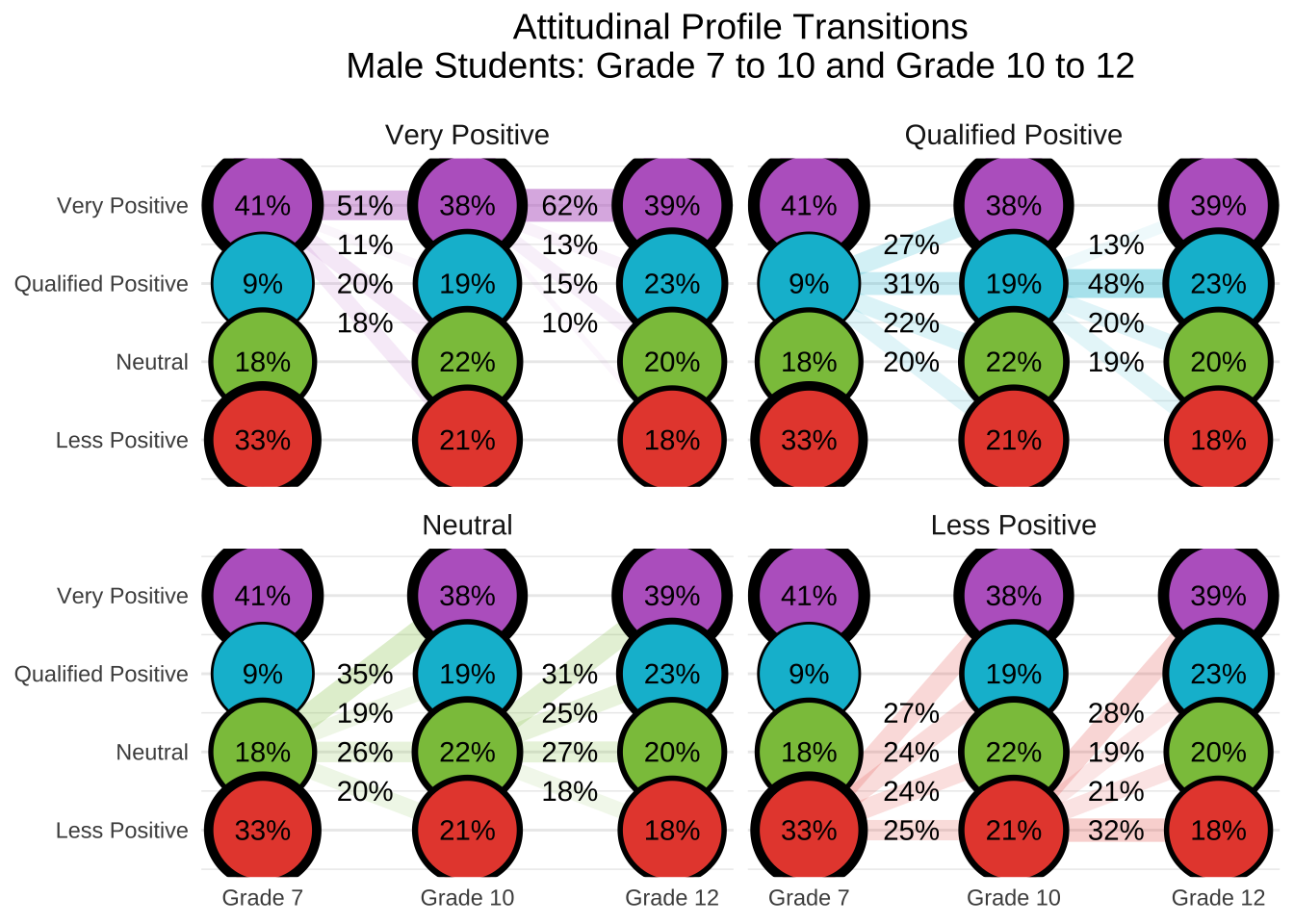
Save plots for males
27.12.4 Examine Transition Probability Plot for Underrepresented Females
merged_female_minority <- merged %>%
filter(FEMALE == 1, MINORITY == 1)
#### 2. Build Mplus-style transition object from modal assignments ####
female_minority_obj <- make_transition_object(merged_female_minority, "N1", "N2", "N3")
#### 3. Assign plot to object with correct facet labels and custom font ####
plot_female_minority <- plot_transitions_function(
model_name = female_minority_obj,
color_palette = class_colors,
facet_labels = c(
`1` = "Very Positive",
`2` = "Qualified Positive",
`3` = "Neutral",
`4` = "Less Positive"
),
timepoint_labels = c(
`1` = "Grade 7",
`2` = "Grade 10",
`3` = "Grade 12"
),
class_labels = names(class_colors)
) +
ggtitle("Attitudinal Profile Transitions\nFemale Minority Students: Grade 7 to 10 and Grade 10 to 12") +
theme(
strip.text = element_text(
family = "Arial",
size = 11,
face = "plain"
),
plot.title = element_text(
family = "Arial",
hjust = 0.5,
size = 14,
margin = margin(b = 10)
),
text = element_text(family = "Arial")
)
#### 4. Display plot ####
plot_female_minority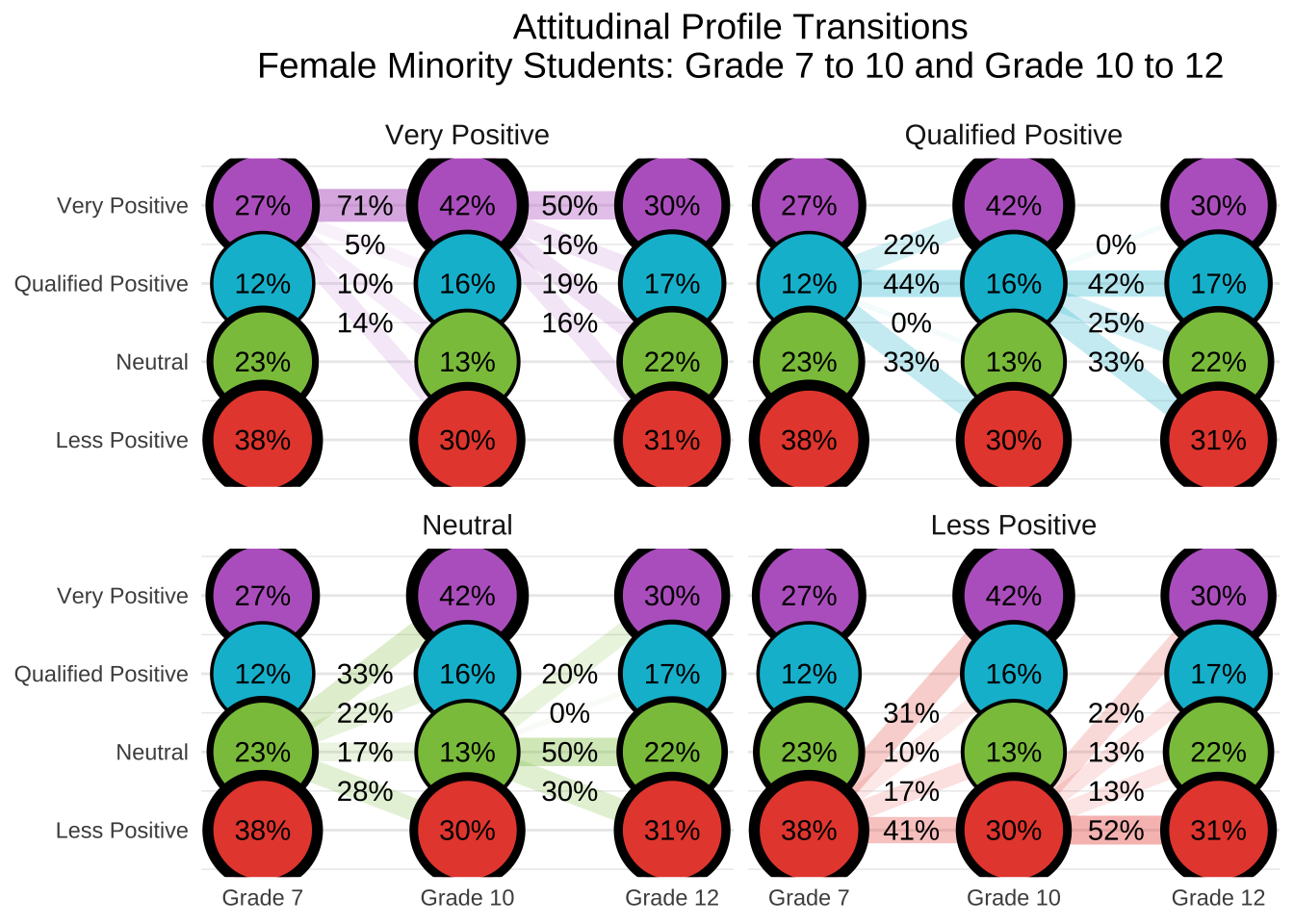
Save plot for minority females
27.12.5 Examine Transition Probability Plot for Non-Underrepresented Females
merged_female_nonminority <- merged %>%
filter(FEMALE == 1, MINORITY == 0)
#### 2. Build Mplus-style transition object from modal assignments ####
female_nonminority_obj <- make_transition_object(merged_female_nonminority, "N1", "N2", "N3")
#### 3. Assign plot to object with labeled facets and Arial font ####
plot_female_nonminority <- plot_transitions_function(
model_name = female_nonminority_obj,
color_palette = class_colors,
facet_labels = c(
`1` = "Very Positive",
`2` = "Qualified Positive",
`3` = "Neutral",
`4` = "Less Positive"
),
timepoint_labels = c(
`1` = "Grade 7",
`2` = "Grade 10",
`3` = "Grade 12"
),
class_labels = names(class_colors)
) +
ggtitle("Attitudinal Profile Transitions\nNon-Minority Female Students: Grade 7 to 10 and Grade 10 to 12") +
theme(
strip.text = element_text(
family = "Arial",
size = 11,
face = "plain"
),
plot.title = element_text(
family = "Arial",
hjust = 0.5,
size = 14,
margin = margin(b = 10)
),
text = element_text(family = "Arial")
)
#### 4. Display plot ####
plot_female_nonminority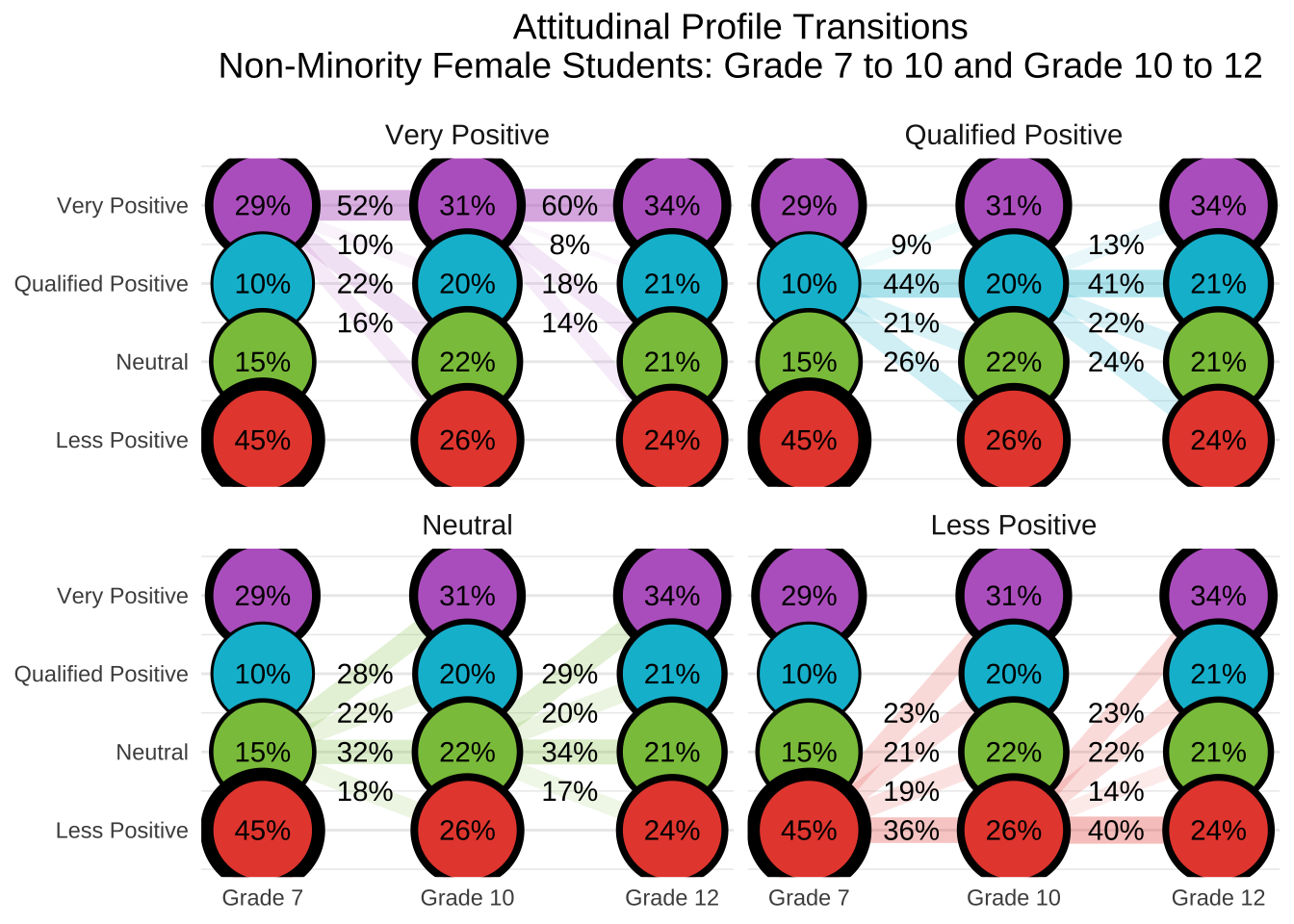
Save plots for non underrepresented females
ggsave(
filename = here("tc_lta","figures", "transitions_female_nonminority.png"),
plot = plot_female_nonminority,
width = 8,
height = 8,
dpi = 300
)27.12.6 Examine table of covariate results for the Step 3 LTA
We next examine the covariate results from the Step 3 LTA, which model how student characteristics predict both profile membership and transitions between profiles over time. The table reports logit estimates, standard errors, and odds ratios with confidence intervals for each covariate effect. These results allow us to identify which background factors are significantly associated with students’ starting profile in Grade 7, and how those factors relate to their likelihood of transitioning to different profiles across timepoints.
# Define class labels
class_names <- c(
"1" = "Low Belonging",
"2" = "Moderate Belonging",
"3" = "High Support",
"4" = "Engaged & Connected"
)
# Build covariate comparison data
covariate_data <- step3_full$parameters$unstandardized %>%
filter(
str_detect(paramHeader, "^C[1-3]#\\d+\\.ON$"),
param %in% c("MINORITY", "FEMALE", "MATHG7", "MATHG10", "MATHG12")
) %>%
mutate(
LatentClass = str_extract(paramHeader, "C[1-3]#\\d+"),
ClassNum = str_extract(LatentClass, "#\\d+") %>% str_remove("#"),
ClassName = class_names[ClassNum],
RefName = class_names["4"],
Comparison = glue("{ClassName} vs. {RefName}"),
Timepoint = case_when(
str_detect(LatentClass, "C1") ~ "Grade 7",
str_detect(LatentClass, "C2") ~ "Grade 10",
str_detect(LatentClass, "C3") ~ "Grade 12"
),
Timepoint = factor(Timepoint, levels = c("Grade 7", "Grade 10", "Grade 12")),
OR = exp(est),
OR_lower = exp(est - 1.96 * se),
OR_upper = exp(est + 1.96 * se),
OR_CI = sprintf("%.2f [%.2f, %.2f]", OR, OR_lower, OR_upper),
Logit = sprintf("%.2f", est),
SE = sprintf("%.2f", se),
pval_fmt = ifelse(pval < .001, "<.001", sprintf("%.3f", pval)),
pval_num = ifelse(pval < .001, 0.0009, pval) # for styling logic
) %>%
arrange(Timepoint, ClassNum) %>%
mutate(RowGroup = glue("{Timepoint}: {Comparison}")) %>%
select(RowGroup, Covariate = param, Logit, SE, `Odds Ratio [95% CI]` = OR_CI, `p-value` = pval_fmt, pval_num)
# Build gt table
covariate_table <- covariate_data %>%
select(-pval_num) %>%
gt(groupname_col = "RowGroup") %>%
tab_header(
title = "Step 3 LTA Covariate Effects",
subtitle = "Log Odds of Class Membership Relative to Engaged & Connected"
) %>%
cols_label(
Covariate = "Covariate",
Logit = "Logit",
SE = "SE",
`Odds Ratio [95% CI]` = "Odds Ratio [95% CI]",
`p-value` = "p-value"
) %>%
tab_style(
style = list(
cell_text(weight = "bold", style = "italic")
),
locations = cells_row_groups()
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(
columns = vars(`p-value`),
rows = covariate_data$pval_num < 0.05
)
)
covariate_table| Step 3 LTA Covariate Effects | ||||
| Log Odds of Class Membership Relative to Engaged & Connected | ||||
| Covariate | Logit | SE | Odds Ratio [95% CI] | p-value |
|---|---|---|---|---|
| Grade 7: Low Belonging vs. Engaged & Connected | ||||
| MINORITY | 0.85 | 0.33 | 2.35 [1.22, 4.52] | 0.011 |
| FEMALE | -0.94 | 0.22 | 0.39 [0.26, 0.60] | <.001 |
| MATHG7 | 0.04 | 0.01 | 1.04 [1.02, 1.07] | <.001 |
| Grade 7: Moderate Belonging vs. Engaged & Connected | ||||
| MINORITY | 0.71 | 0.53 | 2.03 [0.72, 5.71] | 0.182 |
| FEMALE | 0.12 | 0.40 | 1.13 [0.51, 2.48] | 0.769 |
| MATHG7 | 0.00 | 0.02 | 1.00 [0.96, 1.04] | 0.939 |
| Grade 7: High Support vs. Engaged & Connected | ||||
| MINORITY | 0.64 | 0.48 | 1.90 [0.74, 4.86] | 0.182 |
| FEMALE | -0.85 | 0.34 | 0.43 [0.22, 0.84] | 0.013 |
| MATHG7 | -0.03 | 0.02 | 0.97 [0.93, 1.01] | 0.108 |
| Grade 10: Low Belonging vs. Engaged & Connected | ||||
| MINORITY | -0.15 | 0.37 | 0.86 [0.42, 1.76] | 0.675 |
| FEMALE | -0.01 | 0.26 | 0.99 [0.59, 1.66] | 0.962 |
| MATHG10 | 0.02 | 0.01 | 1.02 [1.00, 1.04] | 0.094 |
| Grade 10: Moderate Belonging vs. Engaged & Connected | ||||
| MINORITY | -0.65 | 0.40 | 0.52 [0.24, 1.15] | 0.105 |
| FEMALE | 0.09 | 0.32 | 1.10 [0.58, 2.07] | 0.772 |
| MATHG10 | -0.05 | 0.01 | 0.95 [0.93, 0.98] | <.001 |
| Grade 10: High Support vs. Engaged & Connected | ||||
| MINORITY | -0.40 | 0.50 | 0.67 [0.25, 1.78] | 0.421 |
| FEMALE | -0.10 | 0.35 | 0.90 [0.46, 1.79] | 0.770 |
| MATHG10 | 0.00 | 0.01 | 1.00 [0.97, 1.03] | 0.995 |
| Grade 12: Low Belonging vs. Engaged & Connected | ||||
| MINORITY | -0.37 | 0.41 | 0.69 [0.31, 1.54] | 0.368 |
| FEMALE | -0.30 | 0.31 | 0.74 [0.41, 1.37] | 0.339 |
| MATHG12 | 0.04 | 0.01 | 1.04 [1.01, 1.06] | 0.003 |
| Grade 12: Moderate Belonging vs. Engaged & Connected | ||||
| MINORITY | -0.82 | 0.47 | 0.44 [0.18, 1.10] | 0.079 |
| FEMALE | -0.34 | 0.33 | 0.71 [0.37, 1.37] | 0.308 |
| MATHG12 | -0.02 | 0.01 | 0.98 [0.95, 1.00] | 0.052 |
| Grade 12: High Support vs. Engaged & Connected | ||||
| MINORITY | -0.14 | 0.48 | 0.87 [0.34, 2.23] | 0.776 |
| FEMALE | -0.22 | 0.40 | 0.80 [0.37, 1.74] | 0.578 |
| MATHG12 | -0.01 | 0.01 | 0.99 [0.97, 1.02] | 0.712 |
Save covariate table
27.13 Examine Outcome Variables
In a modern three-step LTA workflow, distal outcomes such as achievement are typically incorporated directly into the third step using model constraints. However, in line with the original paper, we replicate their approach by examining achievement outcomes post hoc using ANOVAs. Specifically, we test whether 12th-grade mathematics and science achievement differ by students’ final attitudinal profile. This allows us to assess the external validity of the profiles by linking them to meaningful academic indicators.
# 1. Prepare variables
merged <- merged %>%
mutate(
traj_final = factor(N3, levels = 1:4),
stable_profile = (N1 == N2 & N2 == N3)
)
# 2. Group means and SDs, exclude 9999 and NA in traj_final
distal_summary <- merged %>%
filter(
MATHG11 != 9999,
SCIG11 != 9999,
!is.na(traj_final)
) %>%
group_by(traj_final) %>%
summarise(
n = n(),
math_mean = mean(MATHG11),
math_sd = sd(MATHG11),
sci_mean = mean(SCIG11),
sci_sd = sd(SCIG11),
.groups = "drop"
)
# 3. Run ANOVAs (excluding 9999)
aov_math <- aov(MATHG11 ~ traj_final, data = merged %>% filter(MATHG11 != 9999))
aov_sci <- aov(SCIG11 ~ traj_final, data = merged %>% filter(SCIG11 != 9999))
# 4. Extract test stats
f_math <- summary(aov_math)[[1]]$`F value`[1]
p_math <- summary(aov_math)[[1]]$`Pr(>F)`[1]
df_math1 <- summary(aov_math)[[1]]$Df[1]
df_math2 <- summary(aov_math)[[1]]$Df[2]
f_sci <- summary(aov_sci)[[1]]$`F value`[1]
p_sci <- summary(aov_sci)[[1]]$`Pr(>F)`[1]
df_sci1 <- summary(aov_sci)[[1]]$Df[1]
df_sci2 <- summary(aov_sci)[[1]]$Df[2]
# 5. Format table
gt(distal_summary) %>%
tab_header(title = "12th Grade Achievement by Final Attitudinal Profile") %>%
fmt_number(columns = ends_with("mean"), decimals = 2) %>%
fmt_number(columns = ends_with("sd"), decimals = 2) %>%
fmt_number(columns = "n", decimals = 0) %>%
cols_label(
traj_final = "Final Profile",
n = "N",
math_mean = "Math M",
math_sd = "Math SD",
sci_mean = "Science M",
sci_sd = "Science SD"
) %>%
tab_source_note(
source_note = glue::glue(
"ANOVA — Math: F({df_math1}, {df_math2}) = {round(f_math, 2)}, p = {format.pval(p_math, digits = 3)}; ",
"Science: F({df_sci1}, {df_sci2}) = {round(f_sci, 2)}, p = {format.pval(p_sci, digits = 3)}"
)
)| 12th Grade Achievement by Final Attitudinal Profile | |||||
| Final Profile | N | Math M | Math SD | Science M | Science SD |
|---|---|---|---|---|---|
| 1 | 297 | 75.71 | 11.39 | 71.20 | 10.53 |
| 2 | 148 | 67.37 | 12.33 | 64.19 | 9.81 |
| 3 | 151 | 69.32 | 13.54 | 66.26 | 12.14 |
| 4 | 161 | 71.15 | 10.42 | 66.20 | 9.55 |
| ANOVA — Math: F(3, 811) = 22.53, p = 5.12e-14; Science: F(3, 815) = 19.82, p = 2.08e-12 | |||||
# 1. Class label mapping
profile_labels <- c(
"1" = "Supportive",
"2" = "Disconnected",
"3" = "Moderate",
"4" = "Negative"
)
# 2. Clean and label profiles
df <- merged %>%
filter(MATHG11 != 9999, SCIG11 != 9999) %>%
mutate(profile = factor(N3, levels = 1:4))
# 3. ANOVA + Tukey — Math
aov_math <- aov(MATHG11 ~ profile, data = df)
tukey_math <- TukeyHSD(aov_math)$profile
tukey_math_df <- as.data.frame(tukey_math) %>%
tibble::rownames_to_column("Comparison") %>%
mutate(
Outcome = "Math",
Group1 = str_match(Comparison, "^(\\d+)-(\\d+)$")[,2],
Group2 = str_match(Comparison, "^(\\d+)-(\\d+)$")[,3],
Comparison = glue("{profile_labels[Group2]} vs. {profile_labels[Group1]}")
) %>%
select(Outcome, Comparison, diff, lwr, upr, `p adj`) %>%
rename(
`Mean Difference` = diff,
`Lower CI` = lwr,
`Upper CI` = upr,
`Adjusted p` = `p adj`
)
# 4. ANOVA + Tukey — Science
aov_sci <- aov(SCIG11 ~ profile, data = df)
tukey_sci <- TukeyHSD(aov_sci)$profile
tukey_sci_df <- as.data.frame(tukey_sci) %>%
tibble::rownames_to_column("Comparison") %>%
mutate(
Outcome = "Science",
Group1 = str_match(Comparison, "^(\\d+)-(\\d+)$")[,2],
Group2 = str_match(Comparison, "^(\\d+)-(\\d+)$")[,3],
Comparison = glue("{profile_labels[Group2]} vs. {profile_labels[Group1]}")
) %>%
select(Outcome, Comparison, diff, lwr, upr, `p adj`) %>%
rename(
`Mean Difference` = diff,
`Lower CI` = lwr,
`Upper CI` = upr,
`Adjusted p` = `p adj`
)
# 5. F values
math_f <- summary(aov_math)[[1]]
sci_f <- summary(aov_sci)[[1]]
# 6. Build Math table
gt_math_table <- gt(tukey_math_df) %>%
tab_header(title = "Pairwise Comparisons for 12th Grade Math Achievement") %>%
fmt_number(columns = c("Mean Difference", "Lower CI", "Upper CI"), decimals = 2) %>%
text_transform(
locations = cells_body(columns = "Adjusted p"),
fn = function(x) ifelse(as.numeric(x) < 0.001, "<.001", formatC(as.numeric(x), format = "f", digits = 3))
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = "Adjusted p", rows = as.numeric(`Adjusted p`) < 0.05)
) %>%
tab_source_note(source_note = md(glue(
"*F*({math_f$Df[1]}, {math_f$Df[2]}) = {round(math_f$`F value`[1], 2)}, *p* = {format.pval(math_f$`Pr(>F)`[1], digits = 3, eps = .001)}"
)))
# 7. Build Science table
gt_sci_table <- gt(tukey_sci_df) %>%
tab_header(title = "Pairwise Comparisons for 12th Grade Science Achievement") %>%
fmt_number(columns = c("Mean Difference", "Lower CI", "Upper CI"), decimals = 2) %>%
text_transform(
locations = cells_body(columns = "Adjusted p"),
fn = function(x) ifelse(as.numeric(x) < 0.001, "<.001", formatC(as.numeric(x), format = "f", digits = 3))
) %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(columns = "Adjusted p", rows = as.numeric(`Adjusted p`) < 0.05)
) %>%
tab_source_note(source_note = md(glue(
"*F*({sci_f$Df[1]}, {sci_f$Df[2]}) = {round(sci_f$`F value`[1], 2)}, *p* = {format.pval(sci_f$`Pr(>F)`[1], digits = 3, eps = .001)}"
)))
# 8. Render both tables
gt_math_table| Pairwise Comparisons for 12th Grade Math Achievement | |||||
| Outcome | Comparison | Mean Difference | Lower CI | Upper CI | Adjusted p |
|---|---|---|---|---|---|
| Math | Supportive vs. Disconnected | −8.34 | −11.41 | −5.27 | <.001 |
| Math | Supportive vs. Moderate | −6.39 | −9.44 | −3.34 | <.001 |
| Math | Supportive vs. Negative | −4.56 | −7.54 | −1.57 | <.001 |
| Math | Disconnected vs. Moderate | 1.95 | −1.57 | 5.48 | 0.483 |
| Math | Disconnected vs. Negative | 3.78 | 0.31 | 7.26 | 0.026 |
| Math | Moderate vs. Negative | 1.83 | −1.63 | 5.28 | 0.523 |
| F(3, 753) = 20.06, p = <0.001 | |||||
gt_sci_table| Pairwise Comparisons for 12th Grade Science Achievement | |||||
| Outcome | Comparison | Mean Difference | Lower CI | Upper CI | Adjusted p |
|---|---|---|---|---|---|
| Science | Supportive vs. Disconnected | −7.01 | −9.74 | −4.28 | <.001 |
| Science | Supportive vs. Moderate | −4.94 | −7.65 | −2.22 | <.001 |
| Science | Supportive vs. Negative | −5.00 | −7.65 | −2.34 | <.001 |
| Science | Disconnected vs. Moderate | 2.07 | −1.07 | 5.21 | 0.324 |
| Science | Disconnected vs. Negative | 2.01 | −1.08 | 5.10 | 0.337 |
| Science | Moderate vs. Negative | −0.06 | −3.14 | 3.01 | 1.000 |
| F(3, 753) = 18.39, p = <0.001 | |||||
27.13.1 Gender Differences in Transition Probabilities
To test for gender differences in attitudinal profile transitions, we computed pairwise z-tests comparing the proportion of female and male students transitioning between each pair of latent classes from Grade 7 to Grade 10. The table below presents cell counts, transition percentages by gender, and two-tailed z-tests for equality of proportions. Statistically significant differences (p < .05) are bolded to highlight transitions where gender-based patterns emerge
# Step 1: Drop invalids and label properly
gender_data <- merged %>%
filter(N1 %in% 1:4, N2 %in% 1:4, FEMALE %in% 0:1) %>%
mutate(
N1 = factor(N1, levels = 1:4),
N2 = factor(N2, levels = 1:4),
FEMALE = factor(FEMALE, levels = 0:1, labels = c("MALE", "FEMALE"))
)
# Step 2: Count transitions
gender_counts <- gender_data %>%
count(N1, N2, FEMALE) %>%
tidyr::pivot_wider(
names_from = FEMALE,
values_from = n,
values_fill = 0
) %>%
rename(n_FEMALE = FEMALE, n_MALE = MALE) %>%
mutate(
p_FEMALE = n_FEMALE / sum(n_FEMALE + n_MALE),
p_MALE = n_MALE / sum(n_FEMALE + n_MALE)
)
# Step 3: z-tests
gender_counts <- gender_counts %>%
mutate(
p1 = n_FEMALE / (n_FEMALE + n_MALE),
p2 = n_MALE / (n_FEMALE + n_MALE),
n1 = n_FEMALE + n_MALE,
se = sqrt((p1 * (1 - p1) / n1) + (p2 * (1 - p2) / n1)),
z = (p1 - p2) / se,
p_val_raw = 2 * (1 - pnorm(abs(z)))
)
# Step 4: Recode class names directly as factors for clean display
gender_counts <- gender_counts %>%
mutate(
N1 = fct_recode(N1,
"Disengaged" = "1",
"Moderate" = "2",
"Positive" = "3",
"Very Positive" = "4"
),
N2 = fct_recode(N2,
"Disengaged" = "1",
"Moderate" = "2",
"Positive" = "3",
"Very Positive" = "4"
)
)
# Step 5: Final display formatting
gender_transition_table <- gender_counts %>%
mutate(
`Female %` = round(p1 * 100, 1),
`Male %` = round(p2 * 100, 1),
`p-value` = ifelse(p_val_raw < 0.001, "<.001", sub("^0", "", sprintf("%.3f", p_val_raw)))
) %>%
select(
`From` = N1, `To` = N2,
n_FEMALE, n_MALE,
`Female %`, `Male %`,
z, `p-value`, p_val_raw
)
# Step 6: Create gt table with italicized labels and bold significant p-values
gt_gender_ztests <- gender_transition_table %>%
gt() %>%
tab_header(title = "Z-Tests for Gender Differences in Transition Probabilities") %>%
fmt_number(columns = c("z"), decimals = 2) %>%
cols_label(
n_FEMALE = md("*n* (Female)"),
n_MALE = md("*n* (Male)"),
z = md("*z*"),
`p-value` = md("*p*-value")
) %>%
opt_row_striping() %>%
tab_style(
style = cell_text(weight = "bold"),
locations = cells_body(
columns = vars(`p-value`),
rows = p_val_raw < 0.05
)
) %>%
cols_hide(columns = p_val_raw)
# View table
gt_gender_ztests| Z-Tests for Gender Differences in Transition Probabilities | |||||||
| From | To | n (Female) | n (Male) | Female % | Male % | z | p-value |
|---|---|---|---|---|---|---|---|
| Disengaged | Disengaged | 115 | 134 | 46.2 | 53.8 | −1.71 | .088 |
| Disengaged | Moderate | 22 | 39 | 36.1 | 63.9 | −3.21 | .001 |
| Disengaged | Positive | 40 | 62 | 39.2 | 60.8 | −3.15 | .002 |
| Disengaged | Very Positive | 45 | 53 | 45.9 | 54.1 | −1.15 | .252 |
| Moderate | Disengaged | 17 | 17 | 50.0 | 50.0 | 0.00 | 1.000 |
| Moderate | Moderate | 46 | 25 | 64.8 | 35.2 | 3.69 | <.001 |
| Moderate | Positive | 18 | 16 | 52.9 | 47.1 | 0.49 | .627 |
| Moderate | Very Positive | 23 | 13 | 63.9 | 36.1 | 2.45 | .014 |
| Positive | Disengaged | 36 | 46 | 43.9 | 56.1 | −1.57 | .116 |
| Positive | Moderate | 31 | 29 | 51.7 | 48.3 | 0.37 | .715 |
| Positive | Positive | 41 | 32 | 56.2 | 43.8 | 1.50 | .133 |
| Positive | Very Positive | 30 | 27 | 52.6 | 47.4 | 0.56 | .574 |
| Very Positive | Disengaged | 82 | 66 | 55.4 | 44.6 | 1.87 | .061 |
| Very Positive | Moderate | 64 | 57 | 52.9 | 47.1 | 0.90 | .367 |
| Very Positive | Positive | 64 | 44 | 59.3 | 40.7 | 2.77 | .006 |
| Very Positive | Very Positive | 126 | 57 | 68.9 | 31.1 | 7.79 | <.001 |