25 Distal Outcomes (Nylund-Gibson, Grimm, & Masyn, 2019)
This chapter replicates the workflow in Nylund-Gibson et al. (2019).
25.1 Data overview
Math attitude indicator:
Five math attitudinal variables were used as the response indicators for the LCA model.
enjoym - I enjoy math.
goodm - I am good at math.
udnerstandm - I usually understand what we are doing in math.
nervousm - Doing math often makes me nervous or upset.
scaredm - I often get scared when I open my math book and see a page of problems.
Covariate:
- female - gender (female = 1; male = 0)
Distal outcomes:
mathjob - Math job (1 = student felt that math was useful for a later job; 0 = student did not feel that math was useful for a later job)
mathirt - Math IRT score in grade 9 (continuous, higher math scores represent higher math achievement)
25.2 Load Packages
library(MplusAutomation)
library(tidyverse)
library(here)
library(glue)
library(gt)
library(cowplot)
library(kableExtra)
library(psych)
library(float)
library(janitor)
library(naniar)25.4 Descriptive Statistics
psych::describe(lsay_df)
#> vars n mean sd median trimmed mad min
#> enjoym 1 2668 0.67 0.47 1.0 0.71 0.00 0.00
#> goodm 2 2670 0.69 0.46 1.0 0.74 0.00 0.00
#> undrstdm 3 2648 0.76 0.43 1.0 0.83 0.00 0.00
#> nervousm 4 2622 0.59 0.49 1.0 0.61 0.00 0.00
#> scaredm 5 2651 0.69 0.46 1.0 0.73 0.00 0.00
#> mathjob 6 2321 0.69 0.46 1.0 0.74 0.00 0.00
#> mathirt 7 2241 58.81 12.60 59.3 58.93 13.49 26.57
#> female 8 3116 0.48 0.50 0.0 0.47 0.00 0.00
#> max range skew kurtosis se
#> enjoym 1.00 1.00 -0.72 -1.49 0.01
#> goodm 1.00 1.00 -0.84 -1.30 0.01
#> undrstdm 1.00 1.00 -1.24 -0.47 0.01
#> nervousm 1.00 1.00 -0.36 -1.87 0.01
#> scaredm 1.00 1.00 -0.81 -1.35 0.01
#> mathjob 1.00 1.00 -0.81 -1.34 0.01
#> mathirt 94.19 67.62 -0.06 -0.55 0.27
#> female 1.00 1.00 0.09 -1.99 0.01
vis_miss(lsay_df)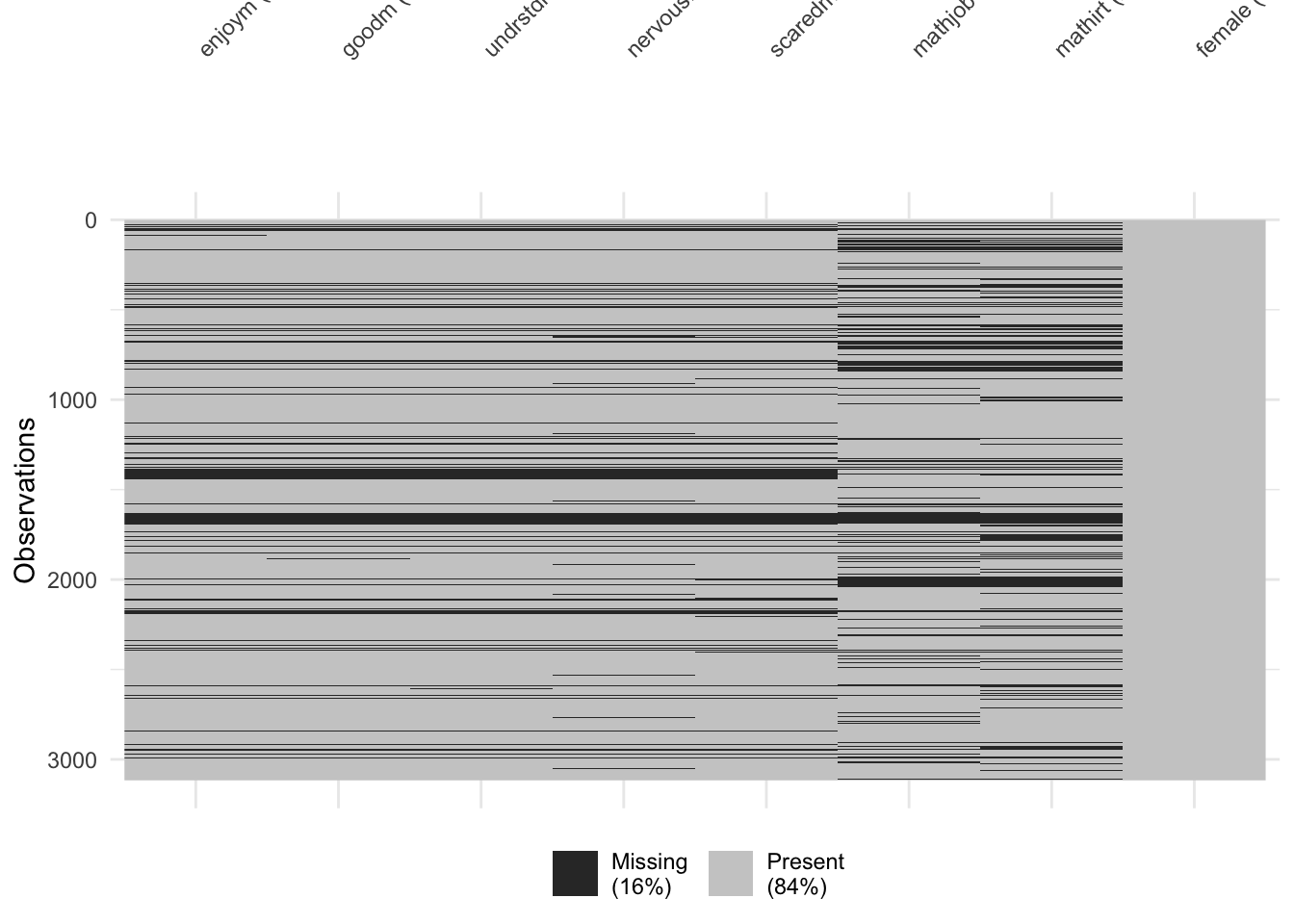
25.5 Enumeration - Maysn (2017)
lca_math <- lapply(1:6, function(k) {
lca_math_enum <- mplusObject(
TITLE = glue("{k}-Class"),
VARIABLE = glue(
"categorical = enjoym-scaredm;
usevar = enjoym-scaredm;
classes = c({k}); "),
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 200 100;
processors = 10;",
OUTPUT = "sampstat residual tech11 tech14 svalues;",
PLOT =
"type = plot3;
series = enjoym-scaredm(*);",
usevariables = colnames(lsay_df),
rdata = lsay_df)
lca_enum_fit <- mplusModeler(lca_math_enum,
dataout=here("distals","enum","enum.dat"),
modelout=glue(here("distals","enum","c{k}_enum.inp")),
check=TRUE, run = TRUE, hashfilename = FALSE)
})25.6 Distal-as-indicator approach
The distal-as-indicator approach, also called the 1-step approach because the latent class variable and the distal outcome means are measured in one modeling step (Vermunt, 2010), the distal outcome is part of the measurement model of the latent variable; that is, the distal outcome is treated as an indicator of the latent class variable (Muthén & Shedden, 1999).
For this model, five math attitude variables, the gender covariate, and the two distal outcomes are included as class indicators.
dasi <- lapply(1:6, function(k) {
lca_enum <- mplusObject(
TITLE = glue("{k}-Class"),
VARIABLE = glue(
"categorical = enjoym-mathjob female;
usevar = enjoym-female;
classes = c({k});"),
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 200 100;
processors = 10;",
OUTPUT = "sampstat residual tech1 tech8 tech10 tech11 tech14 svalues;",
usevariables = colnames(lsay_df),
rdata = lsay_df)
dasi_enum_fit <- mplusModeler(lca_enum,
dataout=here("distals","enum_dasi","dasi.dat"),
modelout=glue(here("distals","enum_dasi","c{k}_dasi.inp")),
check=TRUE, run = TRUE, hashfilename = FALSE)
})25.6.1 Table of fit
source(here("functions", "extract_mplus_info.R"))
# Define the directory where all of the .out files are located.
output_dir <- here("distals", "enum_dasi")
# Get all .out files
output_files <- list.files(output_dir, pattern = "\\.out$", full.names = TRUE)
# Process all .out files into one dataframe
final_data <- map_dfr(output_files, extract_mplus_info_extended)
# Extract Sample_Size from final_data
sample_size <- unique(final_data$Sample_Size)
# Read in .out files into `MplusAutomation`
output_dasi <- readModels(here("distals", "enum_dasi"),
filefilter = "dasi",
quiet = TRUE)
# Extract fit indices
enum_extract <- LatexSummaryTable(
output_dasi,
keepCols = c(
"Title",
"Parameters",
"LL",
"BIC",
"aBIC",
"BLRT_PValue",
"T11_VLMR_PValue",
"Observations"
),
sortBy = "Title"
)
# Calculate additional fit indices
allFit <- enum_extract %>%
mutate(CAIC = -2 * LL + Parameters * (log(Observations) + 1)) %>%
mutate(AWE = -2 * LL + 2 * Parameters * (log(Observations) + 1.5)) %>%
mutate(SIC = -.5 * BIC) %>%
mutate(expSIC = exp(SIC - max(SIC))) %>%
mutate(BF = exp(SIC - lead(SIC))) %>%
mutate(cmPk = expSIC / sum(expSIC)) %>%
dplyr::select(1:5, 9:10, 6:7, 13, 14) %>%
arrange(Parameters)
# Merge columns with LL replications and class size from `final_data`
merged_table <- allFit %>%
mutate(Title = str_trim(Title)) %>%
left_join(
final_data %>%
dplyr::select(
Class_Model,
Perc_Convergence,
Replicated_LL_Perc,
Smallest_Class,
Smallest_Class_Perc
),
by = c("Title" = "Class_Model")
) %>%
mutate(Smallest_Class = coalesce(Smallest_Class, final_data$Smallest_Class[match(Title, final_data$Class_Model)])) %>%
relocate(Perc_Convergence, Replicated_LL_Perc, .after = LL) %>%
mutate(Smallest_Class_Combined = paste0(Smallest_Class, "\u00A0(", Smallest_Class_Perc, "%)")) %>%
dplyr::select(-Smallest_Class, -Smallest_Class_Perc) %>%
dplyr::select(
Title,
Parameters,
LL,
Perc_Convergence,
Replicated_LL_Perc,
BIC,
aBIC,
CAIC,
AWE,
T11_VLMR_PValue,
BLRT_PValue,
Smallest_Class_Combined,
BF,
cmPk
)Create table:
fit_table1 <- merged_table %>%
dplyr::select(
Title,
Parameters,
LL,
Perc_Convergence,
Replicated_LL_Perc,
BIC,
aBIC,
CAIC,
AWE,
T11_VLMR_PValue,
BLRT_PValue,
Smallest_Class_Combined
) %>%
gt() %>%
tab_header(title = md("**Model Fit Summary Table**")) %>%
tab_spanner(label = "Model Fit Indices", columns = c(BIC, aBIC, CAIC, AWE)) %>%
tab_spanner(label = "LRTs",
columns = c(T11_VLMR_PValue, BLRT_PValue)) %>%
tab_spanner(
label = md("Smallest\u00A0Class"),
columns = c(Smallest_Class_Combined)
) %>% # ✅ Non-Breaking Space
cols_label(
Title = "Classes",
Parameters = md("npar"),
LL = md("*LL*"),
Perc_Convergence = "% Converged",
Replicated_LL_Perc = "% Replicated",
BIC = "BIC",
aBIC = "aBIC",
CAIC = "CAIC",
AWE = "AWE",
T11_VLMR_PValue = "VLMR",
BLRT_PValue = "BLRT",
Smallest_Class_Combined = "n (%)"
) %>%
tab_footnote(
footnote = md(
"*Note.* Par = Parameters; *LL* = model log likelihood;
BIC = Bayesian information criterion;
aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion;
AWE = approximate weight of evidence criterion;
BLRT = bootstrapped likelihood ratio test p-value;
VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value;
*cmPk* = approximate correct model probability;
Smallest K = Number of cases in the smallest class (n (%));
LL Replicated = Whether the best log-likelihood was replicated."
),
locations = cells_title()
) %>%
tab_options(column_labels.font.weight = "bold") %>%
fmt_number(columns = c(3, 6:9), decimals = 2) %>%
fmt(
columns = c(T11_VLMR_PValue, BLRT_PValue),
fns = function(x)
ifelse(is.na(x), "—", ifelse(
x < 0.001, "<.001", scales::number(x, accuracy = .01)
))
) %>%
fmt_percent(
columns = c(Perc_Convergence, Replicated_LL_Perc),
decimals = 0,
scale_values = FALSE
) %>%
cols_align(align = "center", columns = everything()) %>%
tab_style(
style = list(cell_text(weight = "bold")),
locations = list(
cells_body(columns = BIC, row = BIC == min(BIC)),
cells_body(columns = aBIC, row = aBIC == min(aBIC)),
cells_body(columns = CAIC, row = CAIC == min(CAIC)),
cells_body(columns = AWE, row = AWE == min(AWE)),
cells_body(
columns = T11_VLMR_PValue,
row = ifelse(
T11_VLMR_PValue < .05 &
lead(T11_VLMR_PValue) > .05,
T11_VLMR_PValue < .05,
NA
)
),
cells_body(
columns = BLRT_PValue,
row = ifelse(BLRT_PValue < .05 &
lead(BLRT_PValue) > .05, BLRT_PValue < .05, NA)
)
)
)
fit_table1| Model Fit Summary Table1 | |||||||||||
| Classes | npar | LL | % Converged | % Replicated |
Model Fit Indices
|
LRTs
|
Smallest Class
|
||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BIC | aBIC | CAIC | AWE | VLMR | BLRT | n (%) | |||||
| 1-Class | 9 | −20,669.36 | 100% | 100% | 41,411.11 | 41,382.51 | 41,420.11 | 41,510.51 | — | — | 3116 (100%) |
| 2-Class | 18 | −19,655.62 | 100% | 100% | 39,456.04 | 39,398.85 | 39,474.04 | 39,654.84 | <.001 | <.001 | 1034 (33.2%) |
| 3-Class | 27 | −19,420.74 | 99% | 100% | 39,058.68 | 38,972.89 | 39,085.68 | 39,356.88 | <.001 | <.001 | 447 (14.4%) |
| 4-Class | 36 | −19,349.10 | 80% | 89% | 38,987.80 | 38,873.41 | 39,023.80 | 39,385.39 | <.001 | <.001 | 491 (15.7%) |
| 5-Class | 45 | −19,331.73 | 34% | 35% | 39,025.45 | 38,882.47 | 39,070.45 | 39,522.45 | 0.29 | <.001 | 182 (5.8%) |
| 6-Class | 54 | −19,313.44 | 31% | 42% | 39,061.27 | 38,889.69 | 39,115.27 | 39,657.66 | 0.12 | <.001 | 258 (8.3%) |
| 1 Note. Par = Parameters; LL = model log likelihood; BIC = Bayesian information criterion; aBIC = sample size adjusted BIC; CAIC = consistent Akaike information criterion; AWE = approximate weight of evidence criterion; BLRT = bootstrapped likelihood ratio test p-value; VLMR = Vuong-Lo-Mendell-Rubin adjusted likelihood ratio test p-value; cmPk = approximate correct model probability; Smallest K = Number of cases in the smallest class (n (%)); LL Replicated = Whether the best log-likelihood was replicated. | |||||||||||
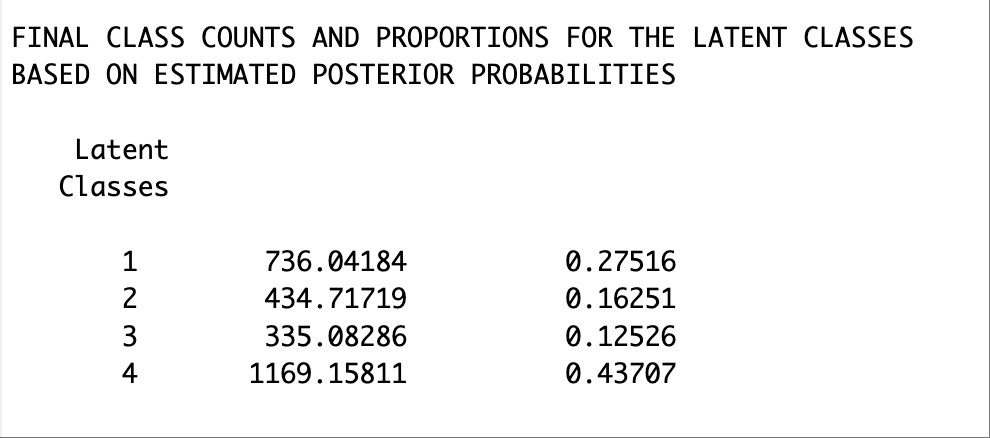
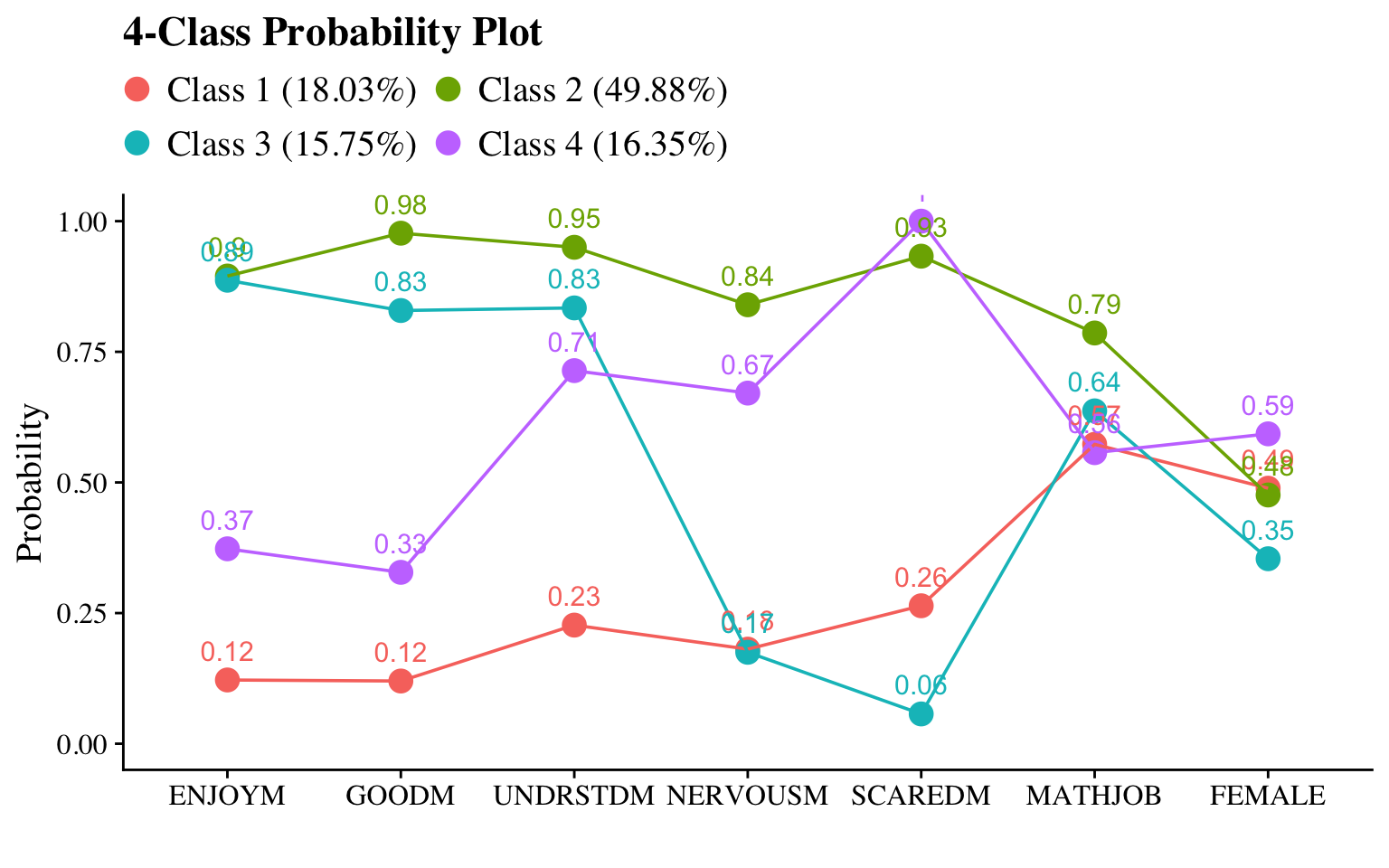
The results from the distal-as-indicator approach suggested a 4-class model as well. Though there were some differences in the emergent latent classes compared to the classes from the unconditional LCA model without distals, the substantive interpretation would largely remain the same with respect to the math attitudinal variables.
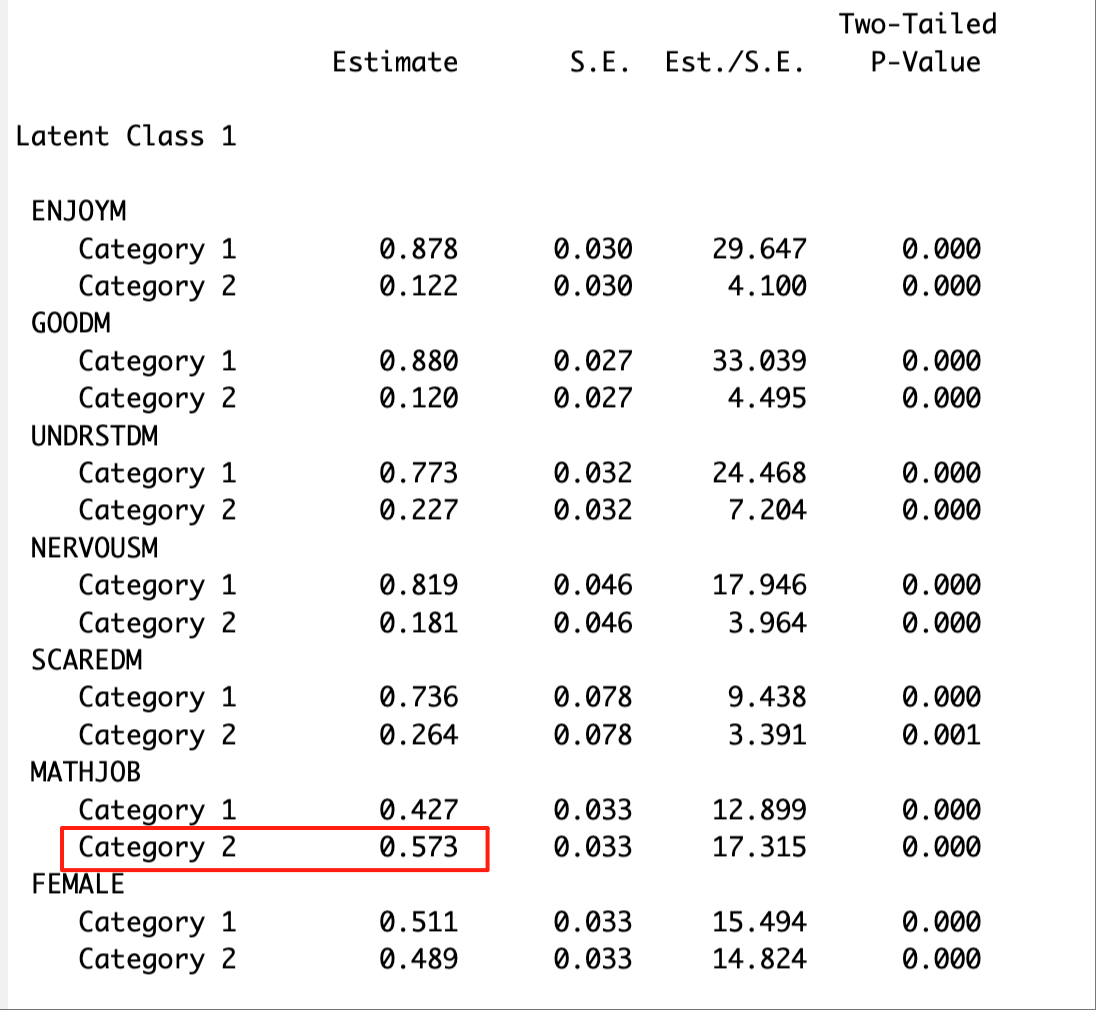
The distal mean of the binary outcome variable (in this case, math job) can be located in the “RESULTS IN PROBABILITY SCALE” section. The excerpt below presents the distal mean of math job for Latent Class 1.
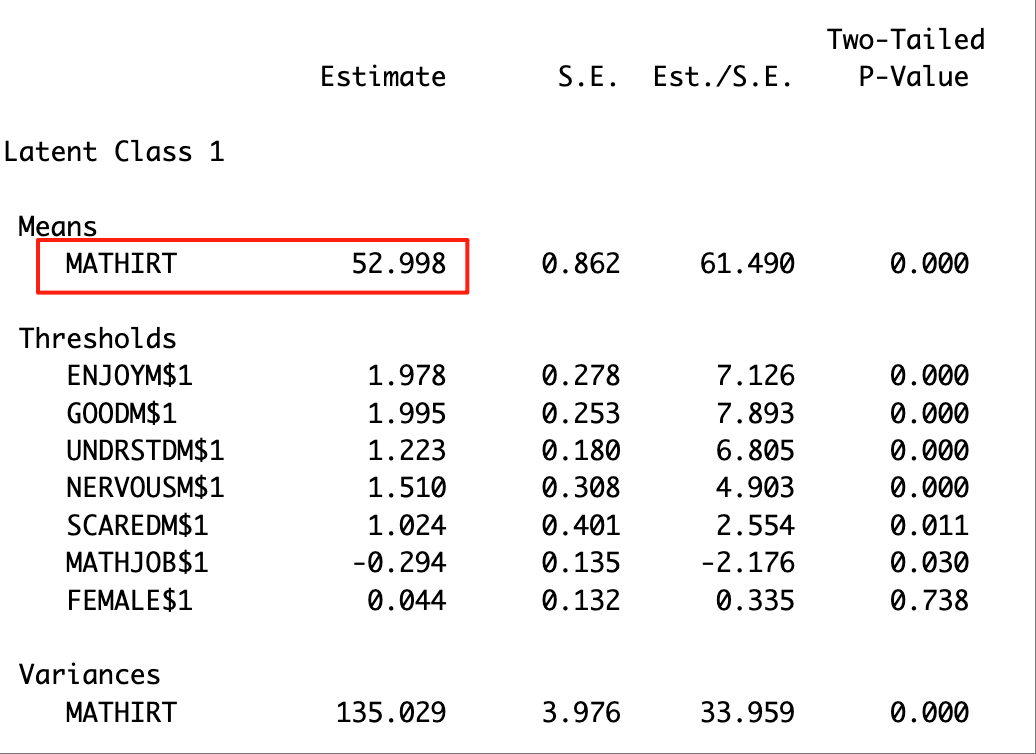
The distal mean of the continuous outcome variable (in this case, math IRT score) can be located in the “MODEL RESULTS” section. The excerpt below shows the distal mean of the math IRT score for Latent Class 1.
25.7 Adding constraints to test the distal means
dasi_cons <- mplusObject(
TITLE = "D as I with constraints",
VARIABLE =
"categorical = enjoym-mathjob female;
usevar = enjoym-female;
classes = c(4);",
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 200 100;
processors = 10;",
MODEL =
" %overall%
%c#1%
[mathjob$1] (dj1);
[mathirt] (dm1);
[female$1] (df1);
%c#2%
[mathjob$1] (dj2);
[mathirt] (dm2);
[female$1] (df2);
%c#3%
[mathjob$1] (dj3);
[mathirt] (dm3);
[female$1] (df3);
%c#4%
[mathjob$1] (dj4);
[mathirt] (dm4);
[female$1] (df4);",
SAVEDATA =
"File=3step_savedata.dat;
Save=cprob;",
OUTPUT = "residual tech11 tech14",
MODELCONSTRAINT =
"New (dj1v2 dj1v3 dj1v4 dj2v3 dj2v4 dj3v4
dm1v2 dm1v3 dm1v4 dm2v3 dm2v4 dm3v4
df1v2 df1v3 df1v4 df2v3 df2v4 df3v4);
dj1v2 = dj1-dj2;
dj1v3 = dj1-dj3;
dj1v4 = dj1-dj4;
dj2v3 = dj2-dj3;
dj2v4 = dj2-dj4;
dj3v4 = dj3-dj4;
dm1v2 = dm1-dm2;
dm1v3 = dm1-dm3;
dm1v4 = dm1-dm4;
dm2v3 = dm2-dm3;
dm2v4 = dm2-dm4;
dm3v4 = dm3-dm4;
df1v2 = df1-df2;
df1v3 = df1-df3;
df1v4 = df1-df4;
df2v3 = df2-df3;
df2v4 = df2-df4;
df3v4 = df3-df4;",
usevariables = colnames(lsay_df),
rdata = lsay_df)
dasi_cons_fit <- mplusModeler(dasi_cons,
dataout=here("distals","constraints","dasi_constraints.dat"),
modelout=here("distals","constraints","dasi_constraints.inp"),
check=TRUE, run = TRUE, hashfilename = FALSE)The significance of the newly specified parameters (e.g., DJ1V2, DM1V2) indicates whether there are statistically significant differences between the latent classes. For example, a significant p-value for DM1V2 suggests a meaningful difference in the distal outcome of the math IRT score between Latent Class 1 and Latent Class 2.
25.8 Manual 3-step
25.8.1 Step 1 Class Enumeration w/ Auxiliary Specification
The first step involves identifying the best-fitting unconditional model and saving the posterior probabilities and modal class assignment for that model (i.e., savedata: save=cprob;) and specifying any distal outcome variables as auxiliary variables so that they are included in the new data file saved in the savedata command.
This step is done after class enumeration. In this example, the four class model was the best. Therefore, we are re-estimating the four-class model using optseed for efficiency. The optseed can be found in the “RANDOM STARTS RESULTS RANKED FROM THE BEST TO THE WORST LOGLIKELIHOOD VALUES” section. Any random start value that yields the best log-likelihood can be used as the optseed, and they should produce identical parameter estimates.
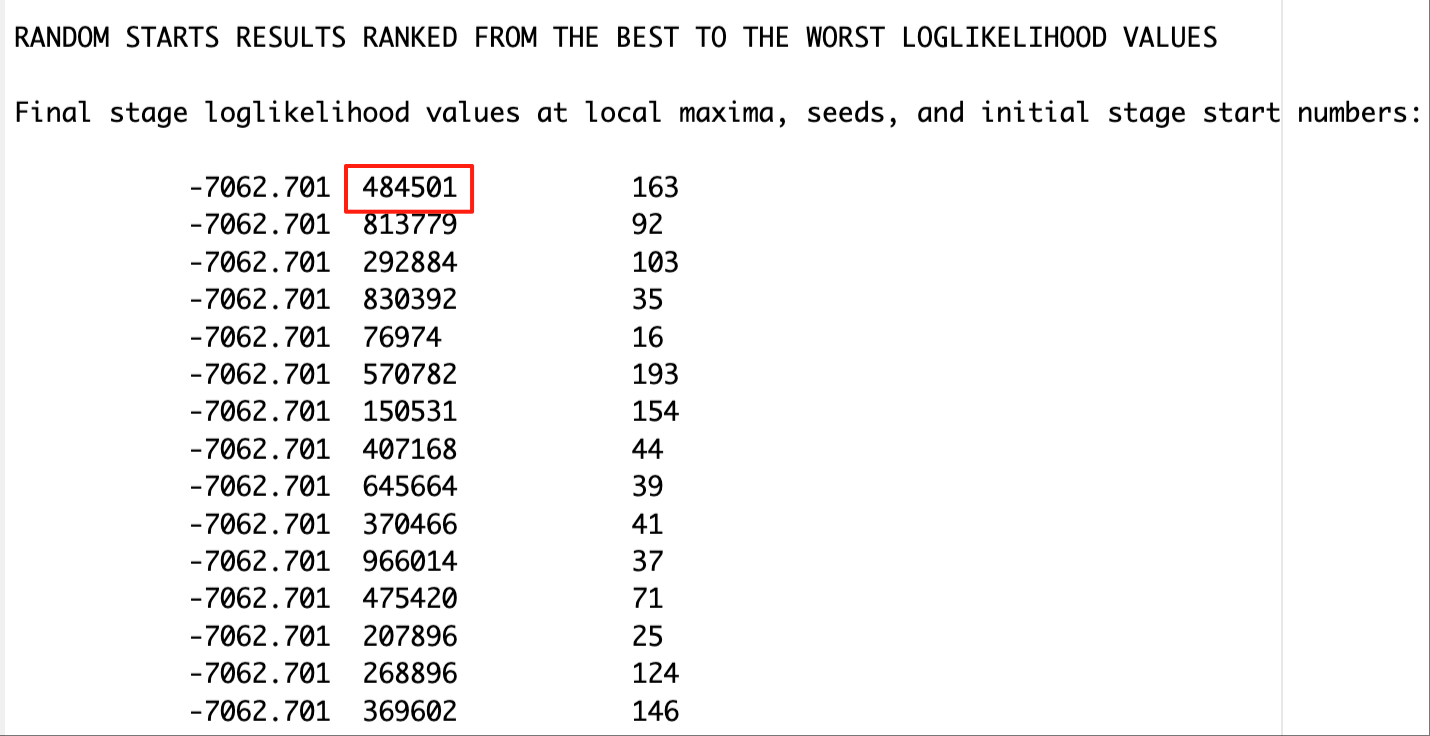
In the SAVEDATA command, we can save the posterior probabilities and the modal class assignment for steps two and three.
ml_step1 <- mplusObject(
TITLE = "Step 1 ",
VARIABLE =
"categorical = enjoym-scaredm;
usevar = enjoym-scaredm;
classes = c(4);
auxiliary = ! list all potential covariates and distals here
female ! covariate
mathjob mathirt; ! distal math test score in 9th grade ",
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 0;
optseed = 484501;",
SAVEDATA =
"File = 3step_savedata.dat;
Save = cprob;",
OUTPUT = "residual tech11 tech14",
usevariables = colnames(lsay_df),
rdata = lsay_df)
ml_step1_fit <- mplusModeler(ml_step1,
dataout=here("distals","three_step","ML_step1.dat"),
modelout=here("distals","three_step","ML_step1.inp") ,
check=TRUE, run = TRUE, hashfilename = FALSE)25.8.2 Step 2 - Determine Measurement Error
output_lsay <- readModels(here("distals","three_step","ML_step1.out"))
logit_cprobs <- as.data.frame(output_lsay[["class_counts"]]
[["logitProbs.mostLikely"]])
savedata_lsay <- as.data.frame(output_lsay[["savedata"]])
colnames(savedata_lsay)[colnames(savedata_lsay)=="C"] <- "N"25.8.3 Step 3 - Add Auxiliary Variables
ML_step3 <- mplusObject(
TITLE = "Step3 ",
VARIABLE =
"nominal = N;
usevar = n;
classes = c(4);
usevar = female mathjob mathirt;" ,
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 100 50;
processors = 4;",
DEFINE =
"center female (grandmean);",
MODEL =
glue(
" %OVERALL%
mathirt on female; ! covariate as a predictor of the distal outcome
mathjob on female;
C on female; ! covariate as predictor of C
%C#1%
[n#1@{logit_cprobs[1,1]}]; ! MUST EDIT if you do not have a 4-class model.
[n#2@{logit_cprobs[1,2]}];
[n#3@{logit_cprobs[1,3]}];
[mathirt](m1); ! conditional distal mean
mathirt; ! conditional distal variance (freely estimated)
[mathjob](j1);
mathjob;
%C#2%
[n#1@{logit_cprobs[2,1]}];
[n#2@{logit_cprobs[2,2]}];
[n#3@{logit_cprobs[2,3]}];
[mathirt](m2);
mathirt;
[mathjob](j2);
mathjob;
%C#3%
[n#1@{logit_cprobs[3,1]}];
[n#2@{logit_cprobs[3,2]}];
[n#3@{logit_cprobs[3,3]}];
[mathirt](m3);
mathirt;
[mathjob](j3);
mathjob;
%C#4%
[n#1@{logit_cprobs[4,1]}];
[n#2@{logit_cprobs[4,2]}];
[n#3@{logit_cprobs[4,3]}];
[mathirt](m4);
mathirt;
[mathjob](j4);
mathjob; "),
MODELCONSTRAINT =
"New (dm1v2 dm1v3 dm2v3 dm1v4 dm2v4 dm3v4
dj1v2 dj1v3 dj2v3 dj1v4 dj2v4 dj3v4
);
dm1v2 = m1-m2; ! test pairwise distal mean differences of IRT score
dm1v3 = m1-m3;
dm2v3 = m2-m3;
dm1v4 = m1-m4;
dm2v4 = m2-m4;
dm3v4 = m3-m4;
dj1v2 = j1-j2; ! test pairwise distal mean differences of math job
dj1v3 = j1-j3;
dj2v3 = j2-j3;
dj1v4 = j1-j4;
dj2v4 = j2-j4;
dj3v4 = j3-j4;",
MODELTEST = " ! omnibus test of distal means
m1=m2;
m2=m3;
m3=m4;
j1=j2;
j2=j3;
j3=j4;",
usevariables = colnames(savedata_lsay),
rdata = savedata_lsay)
step3_fit <- mplusModeler(ML_step3,
dataout=here("distals","three_step","ML_step3.dat"),
modelout=here("distals","three_step","ML_step3.inp"),
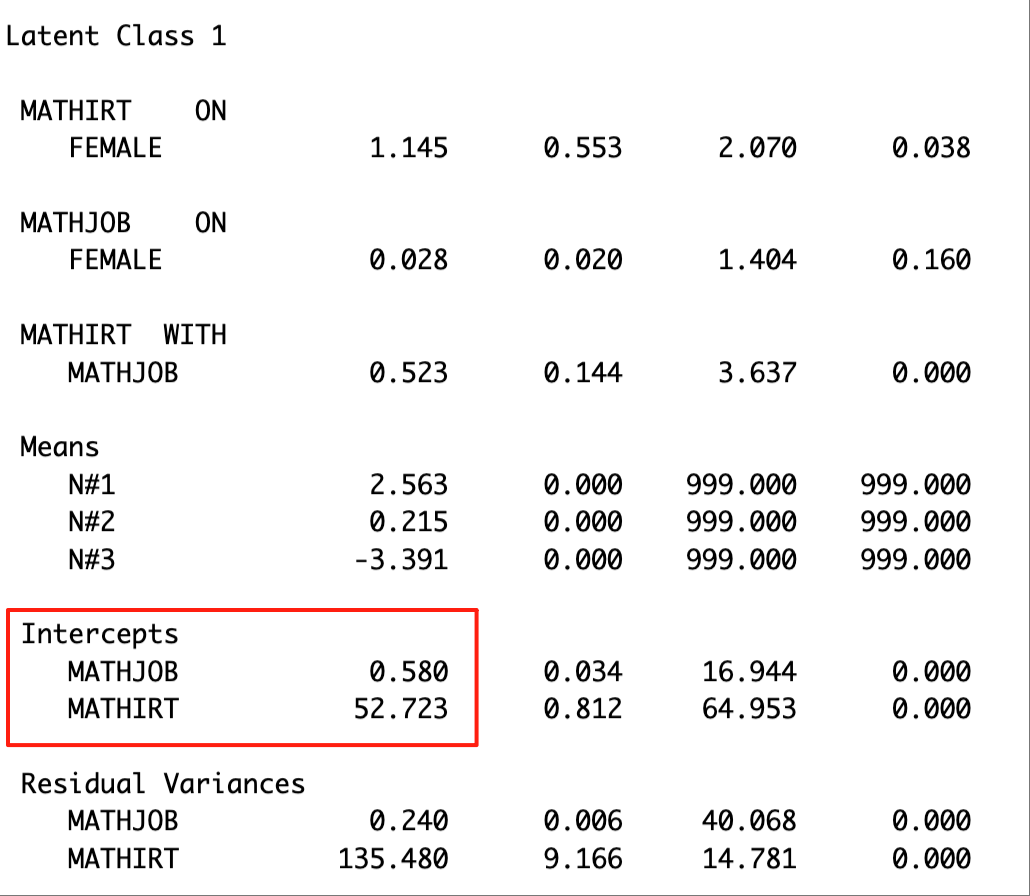
check=TRUE, run = TRUE, hashfilename = FALSE)The distal means of the outcome variables are located in the ‘MODEL RESULTS’ section. The excerpt below presents the distal means of math job and math IRT score for Latent Class 1.
25.9 BCH approach
The BCH method is very similar to the three-step approach except that instead of calculating the average classification error in the second step, classification errors for each individual are computed, and the inverse logits of those individual-level error rates are used as weights in the third step rather than using the modal class assignment as imperfect latent class indicator. Advantages with this approach are that it appears to be more resistant to shifts in the latent classes in the third step (which is a problem in the manual 3-step in Mplus) and can often be used irrespective of variances being equal or unequal across latent classes (which can be a problem with the LTB approach).
25.9.1 Step 1 - Class Enumeration w/ Auxiliary Specification and BCH Weights
step1_bch <- mplusObject(
TITLE = "Step 1 - BCH Method",
VARIABLE =
"categorical = enjoym-scaredm;
usevar = enjoym-scaredm;
classes = c(4);
auxiliary = ! list all potential covariates and distals here
female ! covariate
mathjob mathirt; ! distal math test score in 9th grade ",
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 500 100;",
SAVEDATA =
"File=3step_savedata.dat;
Save=bchweights; ! Here we save the BCH weights
format = free;",
OUTPUT = "sampstat residual tech11 tech14",
PLOT =
"type = plot3;
series = enjoym-scaredm(*);",
usevariables = colnames(lsay_df),
rdata = lsay_df)
step1_fit_bch <- mplusModeler(step1_bch,
dataout=here("distals","three_step","BCH_Step1.dat"),
modelout=here("distals","three_step","BCH_Step1.inp") ,
check=TRUE, run = TRUE, hashfilename = FALSE)25.9.1.1 Step 2 - Extract BCH Weights
Extract saved dataset which is part of the mplusObject “step1_fit_bch”
output_bch <- readModels(here("distals","three_step","BCH_step1.out"))
savedata_bch <- as.data.frame(output_bch[["savedata"]])Rename the column in savedata named “C” and change to “N”
25.9.1.2 Step 3 - Add Auxiliary Variables and BCH Weights
step3_bch <- mplusObject(
TITLE = "Step3 - BCH Method",
VARIABLE =
"classes = c(4);
missing are all(9999);
usevar = BCHW1-BCHW4 mathjob mathirt female;
training = BCHW1-BCHW4(bch);" ,
ANALYSIS =
"estimator = mlr;
type = mixture;
starts = 500 200;",
MODEL =
glue(
" %OVERALL%
mathirt on female; ! covariate as a predictor of the distal outcome
mathjob on female;
C on female; ! covariate as predictor of C
%C#1%
[mathirt](m1); ! conditional distal mean
mathirt; ! conditional distal variance (freely estimated)
[mathjob](j1);
mathjob;
mathirt on female (rm1);
mathjob on female (rj1);
%C#2%
[mathirt](m2);
mathirt;
[mathjob](j2);
mathjob;
mathirt on female (rm2);
mathjob on female (rj2);
%C#3%
[mathirt](m3);
mathirt;
[mathjob](j3);
mathjob;
mathirt on female (rm3);
mathjob on female (rj3);
%C#4%
[mathirt](m4);
mathirt;
[mathjob](j4);
mathjob;
mathirt on female (rm4);
mathjob on female (rj4);"),
MODELCONSTRAINT =
"New (dm1v2 dm1v3 dm2v3 dm1v4 dm2v4 dm3v4
dj1v2 dj1v3 dj2v3 dj1v4 dj2v4 dj3v4
);
dm1v2 = m1-m2; ! test pairwise distal mean differences of IRT score
dm1v3 = m1-m3;
dm2v3 = m2-m3;
dm1v4 = m1-m4;
dm2v4 = m2-m4;
dm3v4 = m3-m4;
dj1v2 = j1-j2; ! test pairwise distal mean differences of math job
dj1v3 = j1-j3;
dj2v3 = j2-j3;
dj1v4 = j1-j4;
dj2v4 = j2-j4;
dj3v4 = j3-j4;",
MODELTEST = " ! omnibus test of distal means
m1=m2;
m2=m3;
m3=m4;
j1=j2;
j2=j3;
j3=j4;
",
OUTPUT = "Tech1 svalues sampstat",
usevariables = colnames(savedata_bch),
rdata = savedata_bch)
step3_fit_bch <- mplusModeler(step3_bch,
dataout=here("distals","three_step","BCH_Step3.dat"),
modelout=here("distals","three_step","BCH_Step3.inp"),
check=TRUE, run = TRUE, hashfilename = FALSE)The distal means of the outcome variables are located in the ‘MODEL RESULTS’ section. The excerpt below presents the distal means of math job and math IRT score for Latent Class 1.
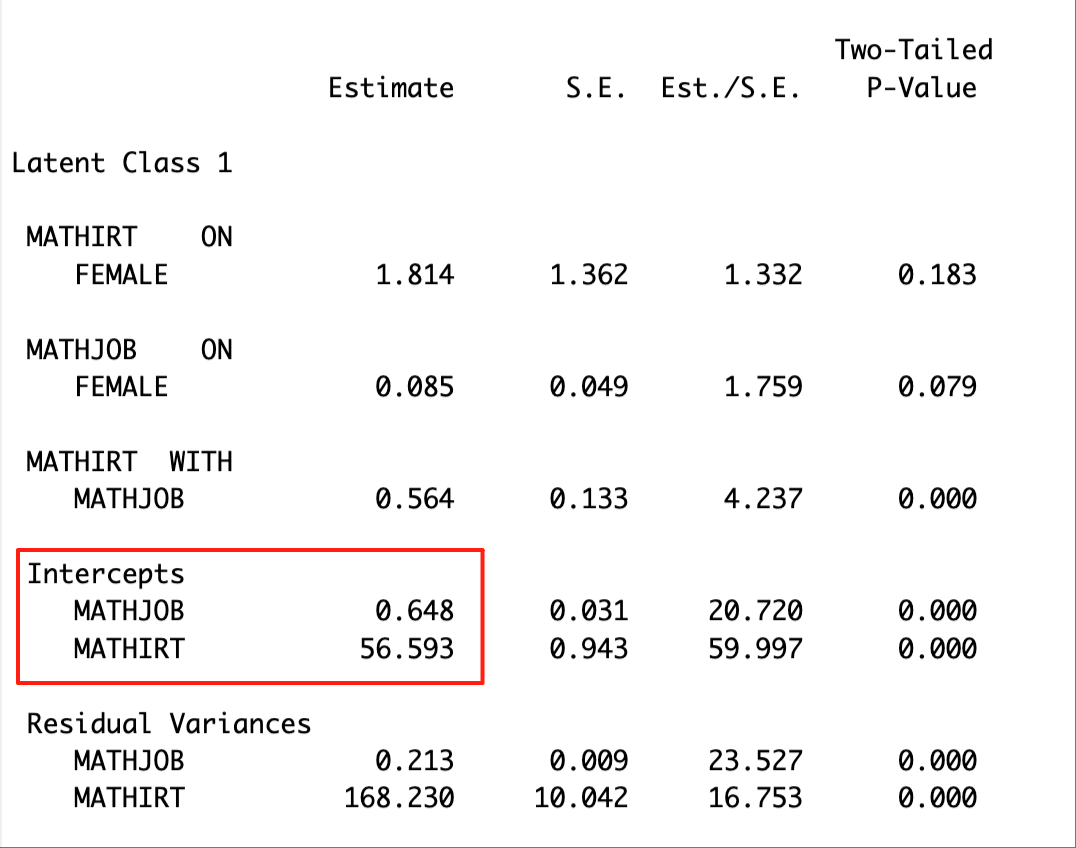
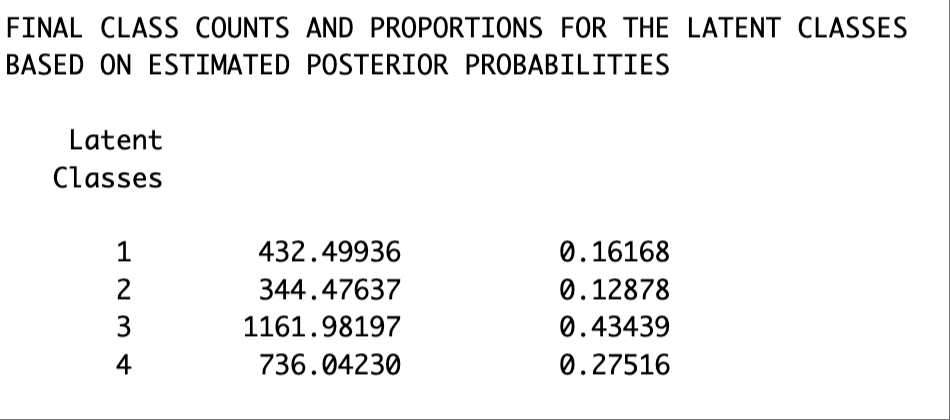
Note that the class numbering may not be consistent across different methods. Check the class proportions to make sure that we are comparing the same class across methods. For example, Latent Class 1 in the BCH results matches the Latent Class 4 in the ML 3-step results..
ML-3 step results
BCH approach results